
2023년 HOT 키워드는 GPT와 같은 대규모 생성형 AI였다. 이번 장에서는 기본적인 생성형 AI에 대해 이해하고 시계열 데이터에서 생성형 AI가 어떻게 이용되는지 알아보고자 한다.
GAN(Generative Adversarial Networks)이란?
오토인코더와 유사한 비지도 학습기법으로 GAN(Generative Adversarial Networks) 알고리즘이 있다. GAN은 생성자와 판별자라는 두 개의 신경망으로 구성된다. 생성자는 랜덤한 분포를 입력받아 실제와 유사한 데이터를 출력한다. 그러면 판별자는 생성자에서 얻은 가짜 데이터와 훈련 데이터에서 추출한 진짜 데이터를 입력받아 해당 데이터가 진짜인지 가짜인지 구별해낸다. 해당 과정을 반복하면 생성자는 점점 실제와 유사한 데이터를 만들어내고 판별자는 점점 더 진짜와 가짜를 잘 구분해낸다. 즉, 두 모델은 경쟁적으로 학습된다. 이렇게 학습이 완료된 생성자가 만약 문장을 생성한다면 그것이 바로 GPT이다.
이처럼 GAN은 아주 획기적 신경망이지만 좋은 GAN 모델을 만들기 위해서는 많은 어려움이 있다. 가장 큰 어려움은 모드붕괴(mode collapse)이다. 이는 생성자 출력의 다양성이 줄어듬을 의미한다.
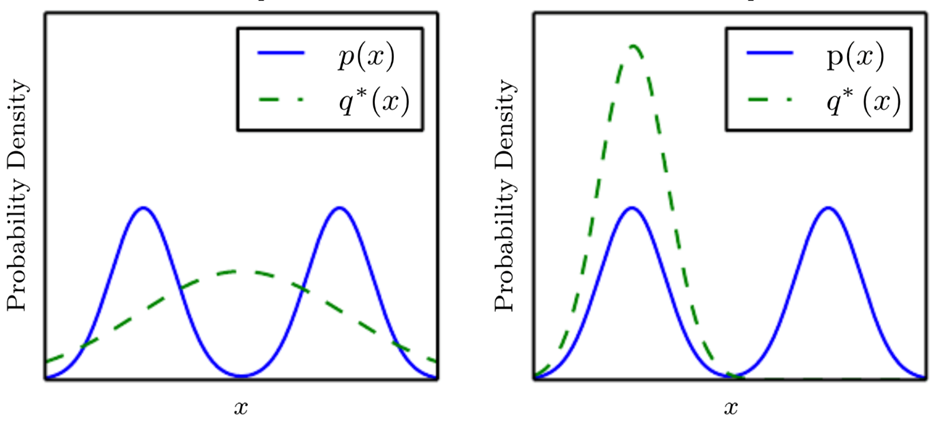
위 그림은 모드붕괴를 나타내고 있다. 파란색 그래프는 실제 데이터의 분포를 의미하고 녹색 그래프는 생성자가 생성한 데이터의 분포이다. 학습 초반에는 왼쪽 그림과 같이 생성자가 넓은 분포의 데이터를 생성하지만 생성자가 어느 한쪽의 실제 분포(그림에서는 왼쪽 분포)를 잡은 이후부터는 판별자 입장에서는 왼쪽은 모두 가짜라고 판단하고 오른쪽은 진짜라고 판단하는 것이 유리하다. 그렇게 되면 생성자는 판별자를 속이기 위해 새로운 데이터(어쩌면 오른쪽 분포)를 생성하게 된다. 그러면 판별자는 이번에는 오른쪽은 모두 가짜라고 판단하고 다른 부분은 진짜로 판단하기 시작한다. 이처럼 학습이 되지 않고 제자리를 빙빙 도는 형태의 문제를 모드붕괴라고 한다. 예컨대 MNIST를 학습한 생성자가 특정 숫자만 생성한다든지 하는 사례가 바로 여기에 속한다. GAN의 문제를 해결하기 위한 노력들이 현재 활발하게 이루어지고 있다. 그 중에서 뛰어난 성과를 보였던 DCGAN(심층 합성곱 GAN)과 관련된 실습을 진행해보자.
실습
이번 실습에서는 DCGAN 알고리즘에 MNIST(0부터 9까지 숫자 이미지) 데이터를 학습시킬 것이다. 이를 통해 GAN에 대한 이해를 깊이한다.
tensorflow를 포함한 실습에 필요한 몇몇 라이브러리를 임포트하였다. MNIST 이미지를 다운로드 받은 후 정규화 및 학습에 이용하기 위해 적당한 배치로 나누었다. 이때, 127.5를 이용해 정규화를 진행함을 확인할 수 있는데 이는 픽셀 값의 분포가 [0,255]이므로 이를 [-1,1]로 옮겨오기 위함이다.

이어서, 생성자 함수를 만들었다. 잡음 50개를 받으면 이를 Conv2DTranspose를 이용해 실제 이미지와 같은 크기인 (28,28,1)의 데이터가 생성된다. 마지막 층을 제외하고는 활성화함수로 LeakyReLU를 이용하는 것과 배치정규화 층이 사이사이에 들어가는 것은 DCGAN의 특징이다. 생성자를 통해 이미지를 생성하면 학습이 되기 전이므로 잡음만을 확인할 수 있다. 해당 잡음 이미지는 실습의 마지막 부분에 첨부했다.

판별자 함수를 만들었다. (28,28,1) 형태의 이미지를 입력받으면 Conv2D, Dense 등의 층을 지나 하나의 실수값을 출력으로 준다. 이 실수값은 [0~1]의 값을 갖는다. 0에 가까울 수록 가짜 데이터의 가능성이 높다고 판단한 것이고 1에 가까울 수록 진짜 데이터일 가능성이 높다고 판단한 것이다.

손실함수를 생성해보자. 판별자 손실함수는 아래의 주석처럼 실제 데이터를 실제라고 판단하는 정도와 가짜 데이터를 가짜라고 판단하는 정도로 결정되고 생성자 손실함수는 가짜를 실제라고 판단하는 정도로 결정된다. 최적함수로는 Adam을 이용하였다.

손실함수를 위와 같이 사용자가 정의할 경우 tensorflow에서 제공하는 compile 메서드를 이용할 수 없다. 대신에 tensorflow는 @tf.function 데코레이터 기능을 제공한다. 이 데코레이터는 함수를 컴파일해준다. 아래의 함수 train_on_batch의 역할은 이름 그대로 batch마다 가중치를 업데이트 해주는 것이다. 먼저, generator에 입력할 잡음을 생성한다. 다음으로 위에서 만든 loss 함수를 이용해 generator와 discriminator의 손실을 구한다. 이때, GradientTape API를 이용하면 좋다. GradientTape는 구문 안에서 실행된 모든 연산을 Tape에 기록한다. 따라서 이후 tape.gradient를 통해 함수의 미분값인 gradient를 쉽게 얻을 수 있다. 획득한 gradient를 apply_gradient를 통해 가중치에 업데이트하면 배치 1개의 학습이 완료된다.

위에서 생성한 여러 함수를 이용하여 학습을 진행하였다.

학습이 완료된 DCGAN을 이용하여 이미지를 생성하였다. 학습이 되기 전과 비교하여 조금 더 숫자와 유사한 이미지를 생성했음을 확인할 수 있다. 학습과정에서 checkpoint를 생성하거나 DCGAN을 더 고도화하면 실제 숫자와 더욱 유사한 이미지를 생성하는 모델을 만들 수 있을 것이다.


TadGAN(Time series Anomaly Detection GAN)
DCGAN 이외에도 PGGAN, STYLEGAN 등 좋은 성능을 보이는 GAN 알고리즘들이 등장하고 있다. GAN은 이미지 분야 뿐만 아니라 시계열 분야에서도 두각을 나타내고 있다. 시계열 이상탐지에 이용하기 위해 개발된 TadGAN 모델에 대해 소개하겠다.

TadGAN은 GAN과 오토인코더의 특성을 합친 모델이다. 기존에 오토인코더 모델은 학습의 능력이 뛰어나지만 이상치가 포함된 데이터의 학습에 매우 취약하였다. 반면, GAN은 특성을 학습하는 능력이 부족하였다. TadGAN은 두 알고리즘의 결합을 통해 적당한 수준의 이상을 탐지한다. 또한, 모드붕괴를 완화시키기 위한 loss를 제안하였다. 아래는 각 신경망에 대한 설명이다.
Cx : 실제 데이터(X)와 잡음을 통해 생성한 가짜 데이터(g(z))를 구분한다.
Cz : 실제 데이터를 압축한 데이터(E(x))와 잡음을 구분한다.
E : 고차원의 subsequence를 저차원으로 인코딩한다.
G : 저차원의 subsequence를 고차원으로 디코딩한다.
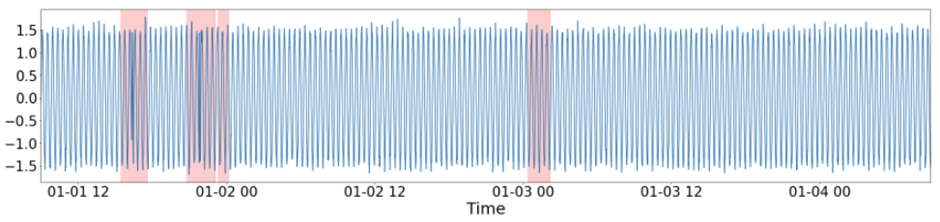
위의 같은 목표를 가지고 각각의 신경망은 경쟁적으로 학습된다. TadGAN의 학습에 이용되는 손실함수는 일반적인 GAN과 차이가 있다. 먼저, TadGAN은 wasserstein GAN에 해당된다. DCGAN과 같이 Discriminator 함수를 이용해 loss를 정의하는 일반적인 GAN을 Vanila GAN이라고 하는데 TadGAN은 실제 데이터 X와 가짜 데이터 G(Z)의 분포를 통하여 loss를 정의한다. 이런 방식의 loss를 사용하는 wasserstein GAN은 모드붕괴를 완화시킨다. 두 번째로, 오토인코더와 합쳐진 모델이므로 GAN loss에 추가로 실제 데이터와 재구축 데이터의 MSE loss를 이용한다. MSE loss는 TadGAN의 특성추출 능력을 높여준다. 학습이 끝난 후 TadGAN은 독자적인 anomaly scoring기법을 통해 이상의 정도를 측정한다. 아래 그림의 파란색 그래프는 실제 데이터이고 노란색은 재구축된 데이터이다. 그리고 붉은색 그래프는 anomaly score를 의미한다.

anomaly score를 바탕으로 TadGAN은 이상을 탐지한다. 아래 그림을 통해 TadGAN이 계절성이 바뀐 부분을 이상으로 탐지했음을 확인할 수 있다.
글을 마무리하며
현재 우리는 인공지능(AI) 시대에 살고 있다. AI 기술은 이미 다양한 분야에서 활용되고 있으며, 특히 이미지 처리, 자연어 처리 등의 연구는 매우 활발하게 진행되고 있다. 시계열 데이터에 대한 연구 역시 꾸준히 진행되고 있으며 다양한 산업 분야에서 두각을 드러내기 시작했다. 엑셈에서 지속 연구 중인 AIOps 솔루션(XAIOps)의 경우 시계열 데이터를 학습한 인공지능이 시스템의 장애를 실시간으로 탐지 및 예측하여 고객의 IT 운영을 효율화하고 시스템의 가용성을 향상시키는데 기여하고 있다. 이 글이 시계열과 인공지능에 관심을 가지고 있는 독자들에게 조금이나마 도움이 되었길 바란다.
* 이미지 출처:
- 모두 붕괴(link)
- TadGAN(link)
글 | AI기술연구2팀임상오

'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 4-6. AutoEncoder(2) (0) | 2024.01.25 |
|---|---|
| Chapter 4-5. AutoEncoder (0) | 2023.12.27 |
| Chapter 4-4. Seq2Seq (0) | 2023.11.30 |
| Chapter 4-3. RNN (0) | 2023.10.26 |
| Chapter 4-2. 기초 베이지안 통계 (0) | 2023.09.21 |




댓글