
Seq2Seq란?
Seq2Seq, 즉 Sequence-to-Sequence는 인코더-디코더 형태의 구조로 이루어져 있어 sequence 형태의 데이터를 처리하는 모델이다.
- 인코더 : 입력 시퀀스로부터 정보를 압축하여 고정된 크기의 문맥 벡터로 변환하는 역할
- 디코더 : 인코더가 전달한 문맥 벡터를 기반으로 출력 시퀀스를 순차적으로 생성하는 역할
그래서 Seq2Seq는 기존의 단순히 LSTM, GRU로만 구성된 모델들에 비해 sequence 데이터를 처리하는 데에 있어 대부분 더 좋은 성능을 발휘하게 된다.
Seq2Seq 구조의 종류
Seq2Seq의 구조는 모델 각각의 입 / 출력 형태에 따라 다양한 종류로 나뉘게 된다.

- one-to-many : vector 형태의 데이터를 입력하여 sequence 형태의 결과를 출력
- many-to-one : sequence 형태의 데이터를 입력하여 vector 형태의 결과를 출력
- many-to-many : sequence 형태의 데이터를 입력하여 sequence 형태의 결과를 출력
실습
다음은 예제를 통해 many-to-many 구조를 활용한 time-series forecasting을 알아보고자 한다.
데이터는 'Minimum Daily Temperatures' 데이터를 사용하였다. (데이터 출처)
필요한 라이브러리 import
import bumpy as np
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, LSTM, Input, RepeatVector
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
데이터 로드 및 데이터 형태 확인
df = pd.read_csv('./public_data/daily-min-temperatures.csv')
df.set_index('Date', inplace=True)
df.head(20)
해당 DataFrame에서 학습하고자 하는 feature가 특정 패턴을 보이는 지 확인하기 위해 plot 함수를 사용하여 시간에 따른 값의 변화를 확인한다.
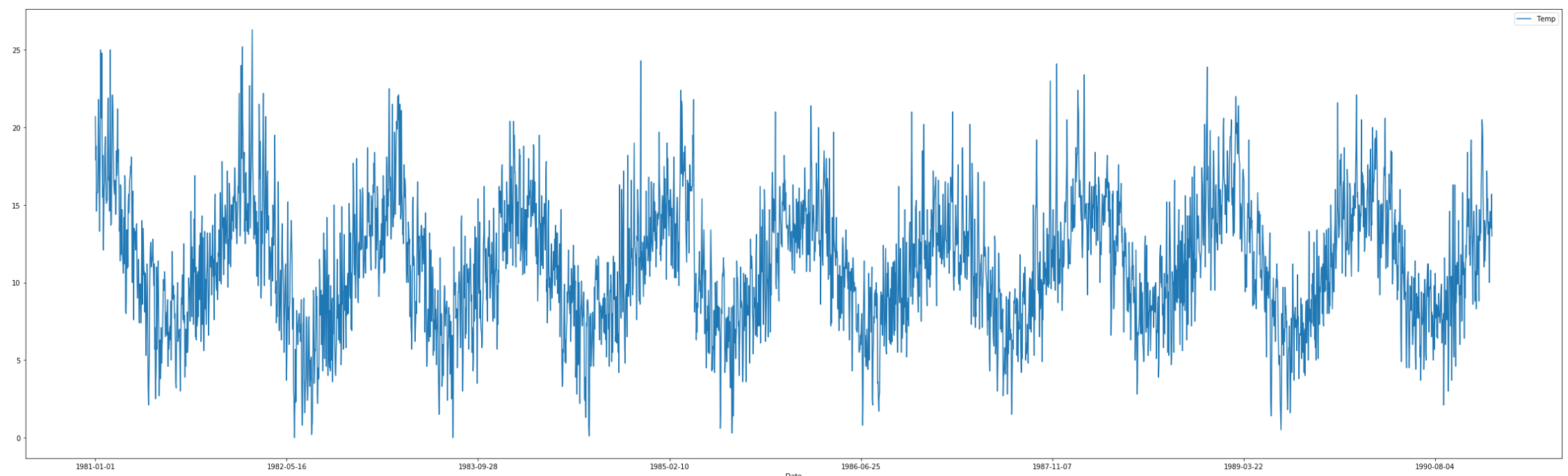
그 후, DataFrame으로부터 데이터를 그대로 사용하지 않고 시계열의 특성이 반영된 sequence 데이터셋으로 재생성 후 모델을 학습시켜야 하고 이를 위해 파라미터 값을 선언한다.
모델의 목적은 과거의 sequence를 통해 미래의 sequence를 예측하는 것이기 때문에, sequence 데이터를 생성할 때 필요한 것은 과거 시점과 미래 시점에서 각각 활용할 특정 길이이다.
그래서 과거 시점에 해당하는 길이를 window_size, 미래 시점은 output_size로 하였고, 각각 10과 5로 하여 이전 10분의 패턴을 통해 미래 5분의 패턴을 예측하게 될 것이다.
또한, 모델 내 각 LSTM 레이어 내 unit값은 64로 한다.
lstm_hidden = 64
window_size = 10
output_size = 5
이후 원활한 학습을 위해 데이터를 스케일링하고, 위의 상수 값들을 활용하여 데이터를 sliding하며 sequence 데이터셋을 생성한다.
scaler = StandardScaler()
data = scaler.fit_transform(df['Temp'].values.reshape(-1, 1)).reshape(-1)
x_data, y_data = [], []
for i in range(df.shape[0] - window_size - output_size + 1):
x_data.append(data[i:i+window_size].reshape(-1, 1))
y_data.append(data[i+window_size: i+window_size+output_size].reshape(-1, 1))
x_data, y_data = np.array(x_data), np.array(y_data)
x_data.shape, y_data.shape
학습과 검증 및 테스트에 사용할 데이터를 분리하기 위해 두 데이터를 train과 test로 분리한다.
x_train, x_test = train_test_split(x_data, test_size=0.2, shuffle=False)
y_train, y_test = train_test_split(y_data, test_size=0.2, shuffle=False)
이전에 선언한 상수 값들을 활용하여 모델을 생성한다.
enc_inp = Input(shape=(window_size, 1))
enc_lstm, enc_h, enc_c = LSTM(lstm_hidden, return_state=True)(enc_inp)
enc_states = [enc_h, enc_c]
dec_inp = RepeatVector(output_size)(enc_h)
dec_lstm = LSTM(lstm_hidden, return_sequences=True)(dec_inp, initial_state=enc_states)
dec_out = Dense(1)(dec_lstm)
model = Model(enc_inp, dec_out)
model.summary()

모델에 사용할 optimizer는 Adam optimizer를 사용하였고 loss 함수로는 MSE를 사용하여 학습하였다.
model.compile(optimizer='adam', loss='mse')
hist = model.fit(x_train, y_train, batch_size=32, epochs=50, validation_data=(x_test, y_test))

다음은 빨간 경계선을 기준으로 좌측은 모델이 학습한 데이터이고, 우측에는 테스트 데이터와 그에 해당하는 모델의 예측값을 나타낸 그래프이다.

다음은 테스트 데이터에 대해 모델이 1분 뒤의 시점에 대한 예측값들과 그에 대응하는 실제 값을 비교한 그래프이다.

이렇게 실습을 통해 시계열 데이터를 가지고 Seq2Seq 모델을 학습시켜 미래 시점에 대한 결과를 예측해보았다. 이후 AutoEncoder 모델을 활용한 이상탐지를 알아보고자 한다.
글 | 신기술본부 AI모델팀 이재빈 님

'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 4-6. AutoEncoder(2) (0) | 2024.01.25 |
|---|---|
| Chapter 4-5. AutoEncoder (0) | 2023.12.27 |
| Chapter 4-3. RNN (0) | 2023.10.26 |
| Chapter 4-2. 기초 베이지안 통계 (0) | 2023.09.21 |
| Chapter 4. 신경망과 딥러닝 (0) | 2023.08.31 |




댓글