
Chapter 4-3. RNN
RNN
우리가 다루는 데이터에는 서로 독립적이지 않고 연관되어 있는 경우가 많다. 예를 들어, 날씨 정보에서 현재 비가 오고 있다면 5분 후에 날씨도 비가 올 것이라고 예측할 수 있다. 또한 이미지 데이터나 문장처럼 데이터의 위치와 순서가 중요한 데이터도 있다. 예를 들어, 이미지 데이터에서 픽셀 단위로 이루어진 고양이 이미지를 순서와 상관없이 혼합해버리면 해당 이미지를 고양이로 이해하기 어려울 것이다. 추가로 문장 데이터를 예로 들면 “나는 구글에서 일한다”라는 문장과 “나는 일할 때 구글을 사용한다”의 문장에서 구글이란 단어는 문자는 같지만 문맥상 다른 의미를 갖는다. 이처럼 시간의 영향을 받거나 위치나 순서가 중요한 데이터를 일반적으로 순차 데이터(sequential data) 혹은 시계열 데이터(time series data)라고 부른다.
RNN(Recurrent Neural Network)이 탄생한 배경은 순차 데이터를 기존의 Feed Forward Network로 학습하기 어렵다는 점이다. 일반적으로 FNN(Feadforward Neural Network) 계열의 신경망은 입력 신호가 다음층으로만 전달되는 단방향 신경망이다. 이런 신경망에선 순차 데이터의 패턴을 충분히 학습하기 어렵다.
RNN 레이어를 하나를 펼쳐보면(unfold) 아래 이미지와 같다.

해당 이미지에서 t 시점의 입력 값 Xt가 모델로 들어갈 때 t-1 시점의 은닉 상태 ht-1도 모델로 같이 전달된다. 여기서 ht-1은 이전 t-1시점의 입력 값인 Xt-1과 ht-2로 만들어진 것이다. 즉 RNN 레이어의 가장 중요한 특징은 이전 시점의 은닉 상태(h)가 입력 값으로 들어오기 때문에 과거의 정보를 사용한다는 점이다.
LSTM/GRU 이론 및 실습
LSTM(Long Short Term Memory)은 RNN의 단점인 기울기 소실(vanishing gradient) 문제를 해결하기 위해 탄생하였다. 기울기 소실 문제는 신경망이 깊어질수록 학습 과정에서 기울기가 0에 수렴하는 문제이다.
LSTM 레이어를 펼쳐보면 아래 이미지와 같다.
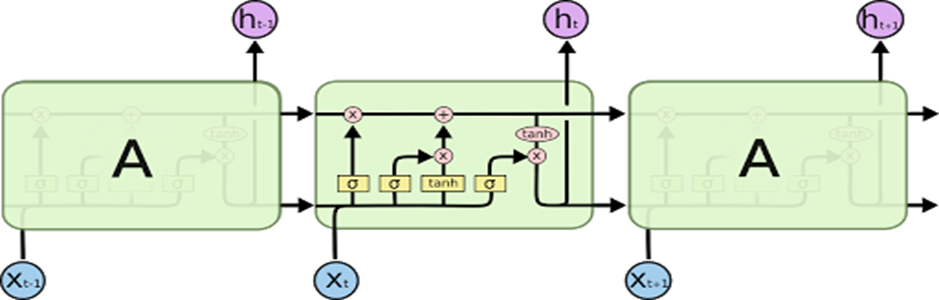
RNN 레이어와 유사하게 t 시점의 입력 값인 Xt와 t-1 시점의 은닉 상태 ht-1이 모델로 전달된다. RNN 레이어와의 차이는 Cell 내부에서 여러 가지 Gate들이 존재한다는 것이다. LSTM Cell의 상세 이미지는 아래와 같다.

LSTM의 핵심은 위 이미지에서 Forget Gate이다. Forget Gate는 말 그대로 과거 정보를 잊기 위한 게이트이다. sigmoid 함수를 적용하면 출력 범위는 0 ~ 1이기 때문에 출력이 0이면 이전 상태의 정보는 잊고, 1이면 이전 상태의 정보를 기억한다. Input Gate에서는 sigmoid 함수를 적용하여 현재 정보를 저장할지 말지 결정하고 출력 범위가 -1 ~ 1인 hyperbolic tangent(tanh) 함수를 사용하여 현재 정보를 얼마나 더할지 결정한다. 마지막으로 Output Gate에서는 hyperbolic tangent(tanh) 함수로 최종적으로 얻어진 cell state 값을 얼마나 사용할지 결정한다. 이 값과 sigmoid 함수를 통해 얻은 출력값과 곱해져 Output state인 yt 와 hidden state인 ht를 출력한다.
이처럼 LSTM은 RNN의 기울기 소실 단점을 해결하기 위해 메모리 셀에 Forget gate, Input gate, Output gate를 추가하여 불필요한 정보는 지우고 기억해야 할 정보들을 가져간다. Forget gate를 이용하여 기억을 장, 단기적으로 저장할 수 있어서 장단기 메모리(Long Short Term Memory)라고 한다.
GRU(Gated Recurrent Units)는 LSTM과 성능은 유사하면서 복잡했던 LSTM의 구조를 간소화한 버전이다.
GRU 레이어를 자세히 살펴보면 아래 이미지와 같다.

LSTM은 Forget, Input, Output 3개의 Gate가 존재했던 반면 GRU에서는 Forget, Input Gate를 합친 Update Gate 그리고 Reset Gate 두 가지만 존재한다.
LSTM Cell에서 두 상태 벡터 Cell state(ct)와 hidden state(ht)가 하나의 hidden state(ht)로 합쳐졌다.
LSTM과 비교해 성능도 유사하지만 Gate의 수가 줄어 학습할 가중치가 적어져 학습 속도가 빠른 장점이 있다.
LSTM, GRU 실습을 위해 Kaggle에서 제공하는 Apple Stock Price from 1980-2021 데이터를 사용하였다.
<LSTM 실습>
import pandas as pd
train_df = pd.read_csv("./AAPL.csv", index_col=0)
데이터 출처
https://www.kaggle.com/datasets/meetnagadia/apple-stock-price-from-19802021?resource=download
Apple Stock Price from 1980-2021
This is Stock Price Dataset of Apple Inc.
www.kaggle.com
위 Kaggle 링크에서 데이터를 다운로드한 후 로컬 위치에 있는 csv 데이터를 로드한다.
train_df 변수를 출력해 보면 데이터를 확인할 수 있다.

train_df = train_df[["High"]].copy()
train_df
여러 컬럼 중 테스트를 위해 High 컬럼을 예측 대상으로 선정하였다.
from sklearn import preprocessing
criteria = '2021-01-01'
scaler = preprocessing.MinMaxScaler()
sequence = 60
batch_size = 64
epoch = 10
verbose = 1
dropout_ratio = 0.2
train = train_df.loc[train_df.index < criteria, :]
test = train_df.loc[train_df.index >= criteria, :]
## Scaling
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
학습 데이터의 스케일링을 위해 scikit learn 라이브러리에서 제공하는 MinMaxScaler를 사용하였다. 스케일러의 종류는 분석가의 실험에 따라 좋은 성능을 갖는 스케일러를 선정할 필요가 있다. 학습 데이터를 순차 데이터(sequence data)로 만들기 위해 sequence 파라미터를 60으로 설정, 기타 딥러닝 학습에 필요한 batch_size나 epoch, dropout_ratio 파라미터들을 설정하였다. batch_size는 학습 데이터의 크기나 학습 속도를 고려하여 적절히 설정할 필요가 있다. criteria라는 학습 데이터와 테스트 데이터를 구분할 기준 시점을 설정 후 데이터를 학습, 테스트 셋으로 구분한다. 추가로 학습, 테스트 데이터 셋을 각각 스케일링한다.
## make sequence data
X_train, Y_train = [], []
for index in range(len(train_scaled) -sequence):
X_train.append(train_scaled[index: index + sequence])
Y_train.append(train_scaled[index + sequence])
X_test, Y_test = [], []
for index in range(len(test_scaled) -sequence):
X_test.append(test_scaled[index: index + sequence])
Y_test.append(test_scaled[index + sequence])
스케일링 된 학습, 테스트 데이터 셋을 이용하여 순차 데이터(sequence data)를 만든다. 순차 데이터란 앞에서 설명한 시간의 영향을 받거나 위치나 순서가 중요한 데이터를 의미한다. 전 단계에서 설정한 sequence 파라미터를 이용해 과거 60일의 데이터로 미래 1일의 데이터를 예측하는 순차 데이터를 만든다.
import numpy as np
## Retype and Reshape
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = np.array(X_test), np.array(Y_test)
print(f"X_train: {X_train.shape}, Y_train: {Y_train.shape}")
print(f"X_train.shape[1] : {X_train.shape[1]}, X_train.shape[2]: {X_train.shape[2]}")
print(f"X_test: {X_test.shape}, Y_test: {Y_test.shape}")
X_train 변수는 과거 60일의 정보를 갖고 있는 3차원 순차 데이터, Y_train 변수는 미래 1일의 정보를 갖고 있는 2차원 순차 데이터이다.
import tensorflow as tf
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.LSTM(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.LSTM(256, return_sequences=True, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.LSTM(128, return_sequences=True, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.LSTM(64, return_sequences=False, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epoch, verbose=verbose)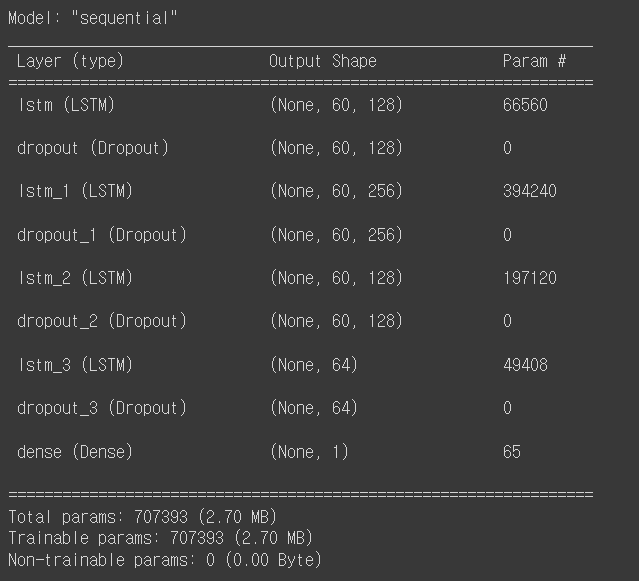
LSTM 멀티 레이어로 구성된 모델을 생성하고 앞에서 전처리한 X_train, Y_train 데이터를 이용하여 학습한다. LSTM 레이어에 사용한 활성화함수로 relu를 사용하였고, 옵티마이저는 adam, loss 함수로는 mse를 사용하였다.
import matplotlib.pyplot as plt
plt.plot(pd.DataFrame(model_fit.history))
plt.grid(True)
plt.show()

모델 학습 후엔 로그를 통해 loss 수치를 직접 확인하거나 그래프를 통해 loss의 감소를 확인할 필요가 있다.
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# inverse scale
Y_train = scaler.inverse_transform(Y_train)
Y_train_pred = scaler.inverse_transform(Y_train_pred)
Y_test = scaler.inverse_transform(Y_test)
Y_test_pred = scaler.inverse_transform(Y_test_pred)
학습을 완료한 모델로 학습 데이터와 테스트 데이터를 대상으로 각각 예측한다. 예측 값은 다시 역스케일링을 통해 원본 데이터와 스케일을 맞춰준다.
train_result_df = pd.DataFrame()
train_result_df["Y_train"] = Y_train.reshape(1, -1)[0]
train_result_df["Y_train_pred"] = Y_train_pred.reshape(1, -1)[0]
test_result_df = pd.DataFrame()
test_result_df["Y_test"] = Y_test.reshape(1, -1)[0]
test_result_df["Y_test_pred"] = Y_test_pred.reshape(1, -1)[0]
실제 데이터와 예측 값 시각화를 위해 학습 데이터와 테스트 데이터 셋 변수를 각각 준비한다.
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(x=train.index.values[:-60], y=train_result_df['Y_train'], name="Y_train"))
fig.add_trace(go.Scatter(x=train.index.values[:-60], y=train_result_df['Y_train_pred'], name="Y_train_pred"))
fig.update_layout(title=f"Train data set")
fig.show()
fig = go.Figure()
fig.add_trace(go.Scatter(x=test.index.values[:-60], y=test_result_df['Y_test'], name="Y_test"))
fig.add_trace(go.Scatter(x=test.index.values[:-60], y=test_result_df['Y_test_pred'], name="Y_test_pred"))
fig.update_layout(title=f"Test data set")
fig.show()

시각화를 위해 ploty-express 라이브러리를 사용하였다, 학습 데이터 셋의 예측 결과와 테스트 데이터 셋의 예측 결과를 각각 시각화하였다. 테스트 데이터 셋에서 예측값과 실제값의 차이는 존재하지만 예측 값이 실제 값의 전체적인 트렌드를 따라가는 것을 확인하였다.
<GRU 실습>
import tensorflow as tf
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.GRU(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.GRU(256, return_sequences=True, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.GRU(128, return_sequences=True, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.GRU(64, return_sequences=False, activation="relu"))
model.add(tf.keras.layers.Dropout(dropout_ratio))
model.add(tf.keras.layers.Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train, batch_size=batch_size, epochs=epoch, verbose=verbose)
GRU 레이어 테스트를 위해 LSTM 모델 생성 코드에서 LSTM 레이어를 GRU 레이어로 교체한다.
모델 학습 완료 후 학습 데이터와 테스트 데이터 셋에 대해 각각 예측한 결과 아래 그래프와 같다. LSTM과 GRU 모델 간 성능 지표를 비교한 결과 동일한 데이터 셋에서 GRU 모델이 좀 더 좋은 성능을 보여주었다.


글 | AI기술연구2팀 김찬경

'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 4-5. AutoEncoder (0) | 2023.12.27 |
|---|---|
| Chapter 4-4. Seq2Seq (0) | 2023.11.30 |
| Chapter 4-2. 기초 베이지안 통계 (0) | 2023.09.21 |
| Chapter 4. 신경망과 딥러닝 (0) | 2023.08.31 |
| Chapter 3-8. 비지도 학습 (0) | 2023.07.26 |




댓글