
Chapter 4. 신경망과 딥러닝
앞서 Chapter 3에서 머신 러닝이 무엇인지 살펴보았다. 이번 챕터에서는 딥 러닝의 정의가 무엇인지에서 시작하여 딥 러닝에 대해 심층적으로 알아보고자 한다.
딥 러닝이란 무엇인가?
딥 러닝은 머신 러닝에 포함된 하위 개념으로 머신 러닝이 알고리즘을 이용해서 데이터를 분석하고, 분석을 통해 학습하여 그것을 기반으로 하여 판단이나 예측을 하는 것인 반면 딥 러닝은 더 나아가 컴퓨터가 사람처럼 인식하고 학습할 수 있는 것을 말한다. 이러한 딥 러닝 알고리즘은 XAIOps의 장단기 부하예측에서 사용하고 있다. 딥 러닝이 무엇인가 알기 위해서는 인공 신경망을 먼저 알아야한다.

인공 신경망은 뇌에 있는 생물학적 뉴런의 네트워크에서 영감을 받은 머신 러닝 모델이다.
뉴런의 구조에서처럼 뉴런은 신호라 부르는 전기 자극을 만들고 이 신호는 축색돌기를 따라 이동하여 시냅스가 신경전달물질이라는 화학적 신호를 발생하게 한다. 이를 통해 감각 기관에서 받아들인 정보가 뉴런을 통해 뇌로 전달된다. 이러한 생물학적 신경망의 원리를 적용한 가장 간단한 인공 신경망 구조가 퍼셉트론이다. 퍼셉트론에 대해 더 자세히 알아보자.
퍼셉트론이란?
퍼셉트론은 앞서 언급했듯이 가장 간단한 인공 신경망 구조 중 하나로 1957년에 프랑크 로젠블라트(Frank Rosenblatt)가 제안했다.

퍼셉트론의 구조에서처럼 다수의 신호를 입력변수로 하나의 신호를 출력변수를 생성하는 구조이다. 여기서 각 입력 신호와 할당된 가중치의 곱을 모두 더해 이것이 임계값을 넘으면 1을 출력하게 된다. 단층 퍼셉트론의 한계에 대해 설명하기위해 논리회로(AND, OR, XOR gate)를 알아보자.
AND gate: \(x_1, x_2\) 둘 다 1일 때만 결과값이 1로 출력되는 게이트
OR gate: \(x_1, x_2\) 둘 중 하나라도 1이면 결과값이 1로 출력되는 게이트
XOR gate: \(x_1, x_2\) 둘 중 하나만 1일 때만 결과값이 1로 출력되는 게이트
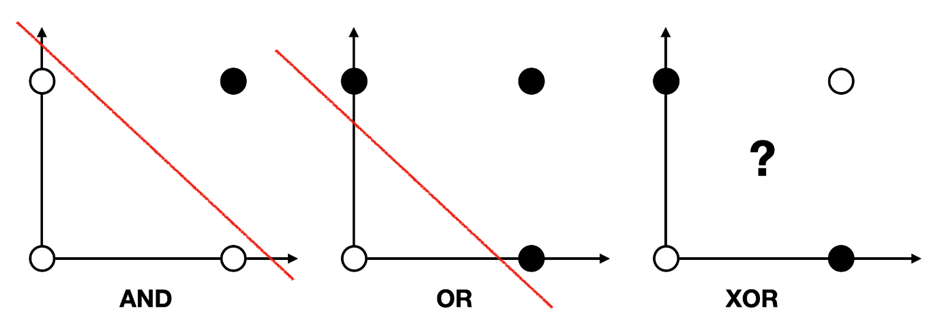
진리표 그림을 보면 AND gate 와 OR gate는 선을 생성하여 결과값이 1인 값을 구별할 수 있지만 XOR gate는 구별할 수 없다. 즉, 단층 퍼셉트론의 선형 계산으로는 XOR gate 문제를 해결할 수 없다. 이 문제 때문에 10년 동안 인공지능의 발달이 늦었지만 이후 다층 퍼셉트론을 통해 이 문제를 해결하였다.

XOR 문제 해결 방법 처럼 종이를 휘어 주는 방법을 통해 해결이 가능하다. 즉, 좌표 평면 자체에 변화를 주는 것이다. NAND, OR gate를 거쳐서 나온 중간 단계에서 한 번 더 AND gate를 넣어주면 XOR gate를 만들 수 있다. 이를 퍼셉트론에 적용하여 그림 4-1-5와 같이 은닉층을 만들어 공간을 왜곡하고 두 개의 퍼셉트론을 한 번에 계산할 수 있게 된다. 다층 퍼셉트론에 대해 더 자세히 알아보자.
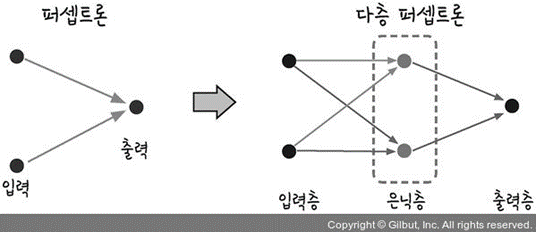
다층 퍼셉트론과 역전파란?
다층 퍼셉트론은 그림 단층 퍼셉트론과 다층 퍼셉트론과 같이 입력층 하나와 은닉층과 출력층으로 구성된다. 보통 입력층에 가까운 층을 하위층이라 하고 출력층에 가까운 층을 상위층이라 한다. 출력층을 제외하고 모든 층은 편향 뉴런을 포함하고 다음 층과 완전히 연결되어 있다. 참고로 앞으로 다룰 심층 신경망(DNN, Deep Neural Network)은 은닉층을 여러 개 쌓아 올린 인공 신경망이다. 이에 대한 구조는 추후에 알아보자. 다층 퍼셉트론의 구조를 알고 난 뒤 한가지의 의문점이 들 것이다. 그림 다층 퍼셉트론만 보면 단순히 계산을 한번 하여 값을 도출하는 것인데 왜 스스로 학습한다고 할까? 이러한 의문은 역전파를 알게 되면 해결될 것이다.

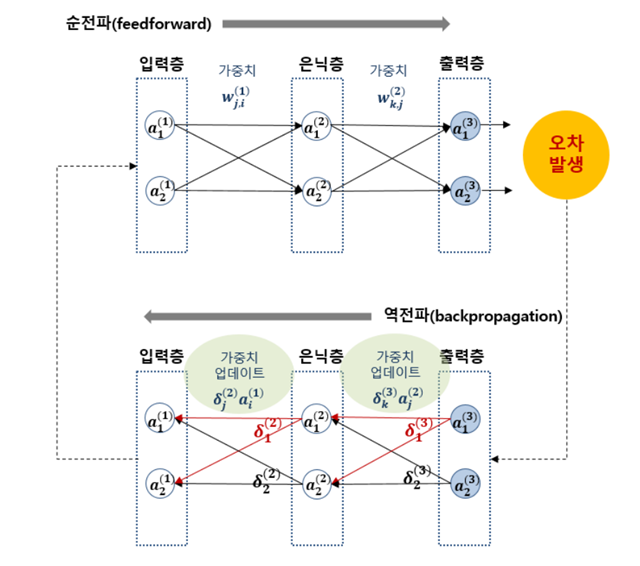
그림 역전파를 보면 역전파에 대해 이해할 수 있을 것이다. 가중치(weight)와 편향(bias)을 실제로 구하기 위해 경사 하강법을 이용한다. 경사 하강법이란 함수의 기울기를 구하고 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복하여 최적화하는 방법을 말한다. 이를 위해 임의의 가중치를 설정하고 결과값을 이용해 오차를 구한다. 오차가 최소가 되는 점(미분했을 때 기울기가 0이 되는 지점)을 찾으면 된다. 결과값의 오차를 구해 하나 앞선 가중치를 차례로 거슬러 올라가며 조정해 나간다. 최적화의 계산 방향이 출력층에서 시작해 입력층으로 역전되어 진행되므로 이를 오차 역전파라 부른다. 역전파의 과정을 다시 한번 정리해 보자면 다음과 같다.
1. 임의의 초기 가중치를 준 뒤 결과(Layout) 계산
2. 계산 결과와 원하는 값 사이의 오차를 구함
3. 경사 하강법을 이용해 바로 앞 가중치를 오차가 작아지는 방향으로 업데이트
4. 오차가 더이상 줄어들지 않을 때까지 반복
이제는 앞에서 언급했던 의문이 풀렸을 것이다. 다층 퍼셉트론은 역전파를 통해 스스로 가중치를 업데이트 하고 학습한다. 다음으로는 활성화 함수에 대해 알아보고자 한다.
활성화 함수란?
활성화 함수란 입력 받은 신호를 학습에 이용할 수 있게 출력 신호로 처리하는 함수를 말한다. 입력 받은 데이터의 활성화 여부를 설정하며, 활성화에 따라 가중치와 최종 결과에 영향을 미친다. 참고로 은닉층에서 선형 함수를 활성화 함수로 사용하게 될 경우 별 의미가 없다. 1차 함수에 1차 함수를 합성하여도 결과는 1차 함수이기 때문이다. 이렇듯 각 활성화 함수마다 특징이 있다. 활성화 함수들을 정리하기에 앞서 활성화 함수는 그레이디언트(gradient, 기울기) 소실과 폭주 문제에 연관성이 많다. 따라서 그레이디언트 소실과 폭주 문제에 대해 잠시 알아보고 활성화 함수의 종류와 특징에 대해 알아보자. 앞에서 말했듯이 알고리즘이 신경망의 모든 파라미터에 대한 오차 함수의 그레이디언트를 계산하면 경사 하강법 단계에서 이 그레이디언트를 사용하여 각 파라미터를 수정한다. 그런데 하위층으로 진행될수록 그레이디언트가 점점 작아지는 경우가 많다. 이에 따라 하위층의 연결 가중치를 변경하지 못하게 되면 학습이 제대로 이루어 졌다고 할 수 없다. 이를 그레이디언트 소멸이라고 한다. 반대로 그레이디언트가 점점 커져서 여러 층이 비정상적으로 큰 가중치로 갱신되면 알고리즘은 발산하게 되는데 이를 그레이디언트 폭주라고 한다. 그레이디언트 폭주는 주로 앞으로 다룰 RNN(순환신경망)에서 주로 나타난다. 이제부터 활성화 함수의 종류에 대해 알아보고 각 함수가 신경망에 어떤 영향을 줄 수 있는지 알아보자.
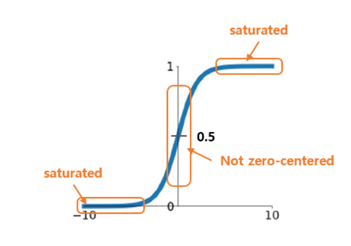
시그모이드 함수는 로지스틱 함수로 불리며 S자 모양이고 연속적이며 미분 가능하다. 입력의 절댓값이 크면 0이나 1로 수렴하게 된다. 이 때는 그레이디언트가 소멸되어 역전파가 불가능 하다. 또 중심이 원점이 아니고 평균이 0.5 이며 항상 양수를 출력하기 때문에 출력의 분산이 입력의 분산보다 크다. 이는 각 레이어를 지날 때 마다 분산이 커져 마지막 레이어에서 활성화 함수가 0이나 1로 수렴한다.
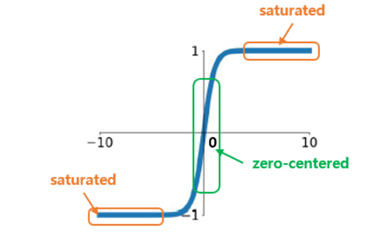
하이퍼볼릭 탄젠트 함수 역시 로지스틱 함수처럼 S자 모양이고 연속적이며 미분 가능하다. 하지만 출력 범위는 -1에서 1사이이다. 특징은 훈련 초기에 각 층의 출력을 원점 근처로 모으는 경향이 있다는 것이다. 이는 빠르게 수렴될 수 있게 해준다. 시그모이드 함수와 마찬가지로 입력의 절댓값이 크면 그레이디언트가 소멸한다.
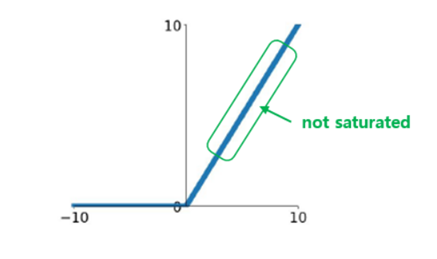
ReLU 함수는 연속적이지만 에서 미분 가능하지 않다. 이는 기울기가 갑자기 변해서 경사 하강법이 튈 수 있다. 또한 입력값이 음수일 때, 도함수는 0이 된다. 실제로 잘 작동하고 계산 속도가 빠르다는 장점이 있어 기본 활성화 함수로 사용된다. 시그모이드 함수와 하이퍼볼릭 탄젠트 함수 보다 수렴 속도가 6배 정도 빠르다. 출력의 최댓값이 없어서 특정 양숫값에 수렴하지 않는다는 장점이 있다. 일 때 0이므로 뉴런이 죽을 수가 있다.

LeakyReLU 함수는 ReLU 함수의 변종으로 가 이 함수가 새는(Leaky) 정도를 결정한다. 여기서 새는 정도란 일 때 기울기이며 일반적으로 0.01을 설정한다. 대부분의 특징은 ReLU와 같고 일 때 0이 아니기 때문에 뉴런이 절대 죽지 않고 언젠가는 깨어날 수 있다.

ELU 함수는 몇 가지를 제외하고 ReLU와 매우 비슷하다. x<0 일 때 음수값이 들어오므로 활성화 함수의 평균 출력이 0에 더 가까워진다. 이는 그레이디언트 소실 문제를 완화해준다. α는 x 가 큰 음수값일 때 ELU가 수렴할 값을 정의한다. 또한 x<0 이어도 그레이디언트가 0이 아니므로 죽은 뉴런을 만들지 않는다. 특히, α=1 이면 원점에서 급격히 변동하지 않아 모든 구간에서 매끄러워 경사 하강법의 속도를 높여준다.
앞으로 다루게 될 심층 신경망(DNN)의 은닉층에는 ELU > LeakyReLU > ReLU > 하이퍼볼릭 탄젠트 > 시그모이드 순으로 많이 사용한다. 하지만 속도가 중요하다면 ReLU가 가장 좋은 선택일 수 있다. 지금까지 신경망의 구조 및 원리에 대해 배웠다. 이제 Keras를 통해 신경망을 직접 구현해보는 일만 남았다. 하지만 인공 신경망은 실습 예제를 생략하고 심층신경망(DNN)에 대해 알아본 뒤 time series 데이터를 활용하여 심층신경망(DNN)으로 예측하는 예제를 실습해보고자 한다.
심층 신경망(DNN, Deep Neural Network)
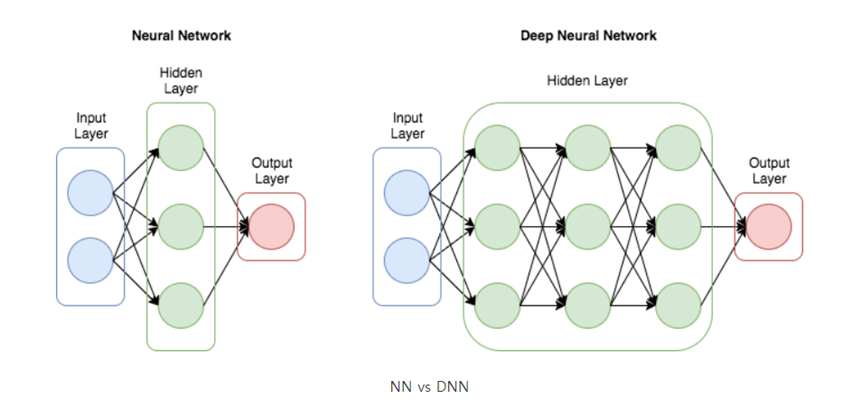
그림 DNN 구조를 보면 알 수 있듯이 심층 신경망이란 입력층과 출력층 사이에 다중의 은닉층을 포함하는 인공 신경망을 말한다. 다중의 은닉층을 포함하여 다양한 비선형적 관계를 학습할 수 있다. 그러나 학습을 위한 많은 연산량과 과하게 학습하여 실제 데이터에 대한 성능이 좋지 못한 과적합 문제, 그레이디언트 소실 및 폭주 문제가 발생할 수 있다. 이러한 문제들과 해결법에 대해 알아보고 DNN을 이용하여 예측하는 예제를 실습해보자.
앞에서 활성화 함수를 다루면서 그레이디언트 소실과 폭주에 대한 설명을 하였기에 생략하고 배치 정규화에 대해 알아보자.
배치 정규화
활성화 함수와 가중치 초기화 전략의 적절한 조합(ELU+He 초기화 전략)으로 훈련 초기 단계에서 어느 정도 그레이디언트 소실이나 폭주 문제를 해결할 수 있다. 하지만 훈련하는 동안 다시 발생하지 않을 거라는 보장은 없다. 이를 해결하기 위한 방법으로 배치 정규화 기법이 나왔다. 활성화 함수를 통과하기 전이나 후에 모델에 연산을 하나 추가한다. 이 연산은 단순하게 입력을 원점에 맞추고 정규화한 다음, 각 층에서 두 개의 새로운 파라미터로 결과값의 스케일을 조정하고 이동시킨다. 많은 경우 신경망의 첫 번째 층으로 배치 정규화를 추가하면 훈련 세트를 표준화할 필요가 없다. 배치 정규화 층이 표준화 역할을 대신한다. 이를 위해 평균과 표준편차를 추정해야 하는데 이를 위해 미니배치에서 입력의 평균과 표준편차를 평가한다. 배치 정규화 알고리즘은 아래와 같다.
$$ 1. \ \ \ \ \mu _\beta = \frac{1}{m_\beta }\sum_{i=1}^{m\beta }x^{(i)} $$ $$ 2. \ \ \ \ \sigma _\beta ^2 =\frac{1}{m\beta }\sum_{i=1}^{m\beta }\left ( x^{(i)} - \mu _\beta \right)^2 $$ $$ 3. \ \ \ \ \hat{x}^{(i)} = \frac{x^{(i)} - \mu \beta }{\sqrt{\sigma \beta ^2 + \varepsilon }} $$ $$ 4. \ \ \ \ z^{(i)} = \gamma \times \hat{x}^{(i)} + \beta $$
\(\mu_{\beta}\) 와 \(\sigma_{\mu}\): 미니배치 B에 대해 평가된 입력의 평균과 표준편차 벡터
\(m_{\beta}\): 미니배치에 있는 샘플 수
\(\hat{x}^{(i)}\) : 샘플 i의 정규화된(평균과 표준편차가 0과1) 입력 벡터
\(\epsilon\) : 안정을 위한 항(smoothing term)으로 분모가 0이 되는 것을 막기 위한 값
\(\gamma\) 와 \(\beta\) : 층의 출력 스케일과 이동 파라미터 벡터
\(z^{(i)}\) : 배치 정규화 연산의 출력 벡터
배치 정규화를 사용하면 그레이디언트 소실 문제가 크게 감소하여 하이퍼볼릭 탄젠트 시그모이드 함수와 같은 수렴성을 가진 활성화 함수를 사용할 수 있다. 또 가중치 초기화에 네트워크가 훨씬 덜 민감하다. 큰 학습률을 사용하여 학습 과정의 속도를 크게 높일 수 있다. 또한 규제와 같은 역할을 하여 다른 규제 기법의 필요성을 줄여준다. 하지만 모델의 복잡도를 키워 실행 시간 면에서 손해를 본다.
그레이디언트 클리핑
역전파될 때 임계값을 넘어서지 못하게 그레이디언트를 잘라내는 기법이다. 그레이디언트 폭주를 완화시키며 앞으로 다룰 순환신경망(RNN)에서는 배치 정규화 적용이 어렵기 때문에 이 방법을 많이 사용한다. 케라스에서 그레이디언트 클리핑을 구현하려면 옵티마이저를 만들 때 clipvalue와 clipnorm 매개변수를 지정하면 된다.
지금까지 그레이디언트 소실과 폭주 문제에 대한 해결방법에 대해 알아보았다. 다음으로 다루어 볼 주제는 속도와 관련된 이야기이다. 아주 큰 심층 신경망의 훈련 속도는 심각하게 느릴 수가 있다. 앞에서 다루었던 연결 가중치에 좋은 초기화 전략 사용, 좋은 활성화 함수 사용, 배치 정규화 사용으로 이를 해결할 수 있지만 훈련 속도를 크게 높일 수 있는 또 다른 방법이 있다. 표준적인 경사 하강법 옵티마이저(SGD) 대신 더 빠른 옵티마이저를 사용하는 것이다. 이제부터 고속 옵티마이저에 대해 알아보자.
고속 옵티마이저
모멘텀 최적화(Momentum Optimizer)
일반적인 경사 하강법은 가중치에 대한 비용 함수의 그레이디언트에 학습률을 곱한 것을 바로 차감하여 가중치를 갱신한다. 이 식은 이전 그레이디언트가 얼마였는지 고려하지 않지만, 모멘텀 최적화는 이전 그레이디언트가 얼마였는지를 고려해서 가중치를 수정한다. 일종의 마찰저항을 표현하고 모멘텀이 너무 커지는 것을 막기 위해 모멘텀이라는 하이퍼파라미터 를 사용한다. 모멘텀 최적화를 사용하면 경사 하강법 보다 더 빠르게 평평한 지역을 탈출할 수 있다. 또한, 이 기법은 지역 최적점을 건너뛰도록 하는 데도 도움을 준다. 일반적으로 모멘텀 값은 0.9이며 보통 잘 작동하고 경사 하강법보다 거의 항상 더 빠르다.
네스테로프 가속 경사(NAG)

네스테로프 가속 경사는 1983년 유리 네스테로프가 제안한 모멘텀 최적화의 변종이다. 그림 네스테로프 가속 경사를 보면 알 수 있듯이 원래 위치의 그레이디언트가 아닌, 모멘텀의 방향으로 조금 더 나아가 측정한 그레이디언트를 사용한다. 일반적으로 모멘텀 벡터가 올바른 방향(즉, 최적점을 향하는 방향)을 가리킬 것이므로 이런 변경이 가능하다. 이 방법은 기본 모멘텀 최적화보다 거의 항상 더 빠른 성능을 보여준다.
AdaGrad
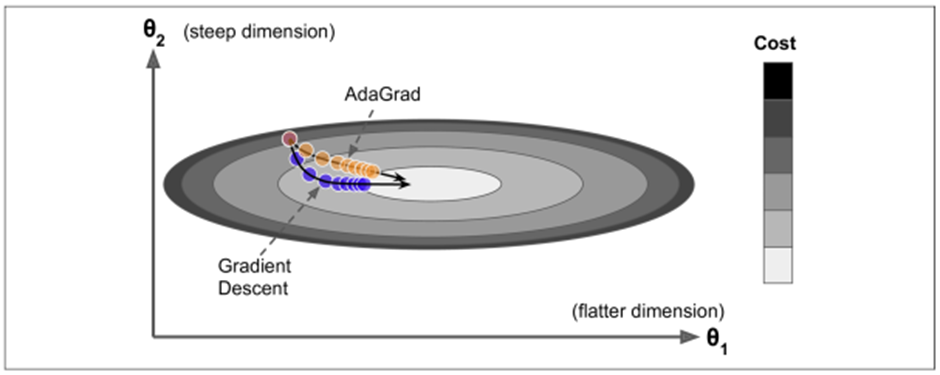
그림 AdaGrad 처럼 한쪽이 길쭉한 그릇 문제를 생각해보자. 경사 하강법은 전역 최적점 방향으로 곧장 향하지 않고 가장 가파른 경사를 따라 빠르게 내려가기 시작해서 골짜기 아래로 느리게 이동한다. AdaGrad 알고리즘은 가장 가파른 차원을 따라 그레이디언트 벡터의 스케일을 감소시켜 이 문제를 해결한다. 이 알고리즘은 학습률을 감소시키지만 경사가 완만한 차원보다 가파른 차원에 대해 더 빠르게 감소된다. 이를 적응적 학습률(Adaptive Learning rate)이라고 부르며, 전역 최적점 방향으로 바로 가도록 한다. 하지만, AdaGrad는 심층 신경망을 훈련할 때 너무 일찍 멈추는 경우가 있으므로, 간단한 2차 방정식 문제나 선형 회귀 같은 간단한 작업에 사용하는 것이 좋다.
RMSProp
AdaGrad는 너무 빨리 느려져서 전역 최적점에 수렴하지 못하는 위험이 있다. RMSProp
알고리즘은 훈련 시작부터의 모든 그레이디언트가 아닌 가장 최근 반복에서 비롯된 그레이디언트만 누적함으로써 이 문제를 해결하였다. 이를 위해 알고리즘의 첫 번째 단계에서 지수 감소를 사용한다. 보통 감쇠율 β 는 0.9로 설정한다. 기본값이 잘 작동하는 경우가 많아 이를 튜닝할 필요가 거의 없다. 아주 간단한 문제를 제외하고는 AdaGrad보다 훨씬 더 성능이 좋다.
Adam
적응적 모멘트 추정(adaptive moment estimation)을 의미하는 Adam은 모멘텀 최적화와 RMSProp의 아이디어를 합친 것이다. 모멘텀 최적화처럼 지난 그레이디언트의 지수 감소 평균을 따르고 MRSProp처럼 지난 그레이디언트 제곱의 지수 감소된 평균을 따른다. 적응적 학습률 알고리즘이기 때문에 학습률 하이퍼파라미터를 튜닝할 필요가 적다. 기본값 0.001을 일반적으로 사용하면 경사 하강법보다도 더 사용하기 쉽다.
Nadam은 Adam의 변종으로 Adam 옵티마이저에 네스테로프 기법을 더한 것이다. 따라서 종종 Adam보다 조금 더 빠르게 수렴한다.
AdaMax
Adam과 같은 논문에서 소개된 알고리즘으로 Adam에서 s에 그레이디언트의 제곱, 즉 노름을 누적하는 대신 노름으로 바꾸어 시간에 따라 감소된 그레이디언트의 최댓값으로 조정한다. 실전에서 Adam보다 안정적이나 일반적으로 Adam의 성능이 더 낫다. Adam이 잘 작동하지 않을 경우 시도해 볼만 하다.
만약, RMSProp, Adam, Nadam 최적화를 포함하여 적응적 최적화 방법이 좋은 성능을 내지 못한다면, 단순 모멘텀 최적화 방식인 네스테로프 가속 경사를 사용해 보는 것도 좋은 방법이 될 수 있다. 각 옵티마이저의 수렴 속도 및 품질을 그림으로 정리해보았다.

만약, RMSProp, Adam, Nadam 최적화를 포함하여 적응적 최적화 방법이 좋은 성능을 내지 못한다면 단순 모멘텀 최적화 방식인 네스테로프 가속 경사를 사용해 보는 것도 좋은 방법이 될 수 있다.
학습률 스케줄링
좋은 학습률을 찾는 것은 매우 중요하다. 학습률을 너무 크게 잡으면 훈련이 실제로 발산할 수 있고 너무 작게 잡으면 최적점에 수렴하겠지만 시간이 매우 오래 걸린다. 매우 작은 값에서 매우 큰 값까지 지수적으로 학습률을 증가시키면서 모델 훈련을 수백 번 반복하여 좋은 학습률을 찾을 수 있다. 그 후 학습 곡선을 살펴보고 다시 상승하는 곡선보다 조금 더 작은 학습률을 선택한다. 그 다음 모델을 다시 초기화하고 이 학습률로 훈련한다. 이보다 더 좋은 방법은 큰 학습률로 시작하고 학습 속도가 느려질 때 학습률을 낮추면 최적의 고정 학습률보다 좋은 솔루션을 더 빨리 발견할 수 있다. 훈련하는 동안 학습률을 감소시키는 전략에는 여러 가지가 있다. 이런 전략을 학습 스케줄이라고 한다. 성능 기반 스케줄링과 지수 기반 스케줄링 둘 다 잘 작동하지만 튜닝이 쉽고 최적점에 조금 더 빨리 수렴하는 지수 기반 스케줄링이 선호된다. 하지만 1사이클 방식이 조금 더 좋은 성능을 낸다
규제를 사용해 과대적합 피하기
심층신경망은 전형적으로 수만 개, 수백만 개의 파라미터를 가지고 있기 때문에 자유도가 매우 높은 네트워크이다. 이러한 높은 자유도는 네트워크를 훈련 세트에 과대적합되기 쉽게 만들고, 이에 따른 여러 규제 방법이 존재한다. 앞서 소개한 배치정규화(BN) 외에도 널리 사용되는 다른 규제 방법을 알아보자.
드롭아웃

드롭아웃은 심층 신경망에서 가장 인기 있는 규제 기법 중 하나이다. 그림 드롭아웃과 같이 매 훈련 스텝에서 각 뉴런은 임시적으로 드롭아웃 확률 p에 따라 일부 뉴런을 비활성화 시킨다. 이런 파괴적인 방식이 잘 작동할지 의문이 들겠지만 의외로 신경망에선 확실한 성과를 낸다. 드롭아웃을 사용하면 입력값의 작은 변화에 덜 민감해지기 떄문에 보다 일반화된 네트워크를 만들 수 있다. 따라서 모델이 과대적합되었다면 드롭아웃 비율을 늘려 더 많은 노드를 비활성화시키면 된다. 한 가지 중요한 기술적인 세부사항이 있다. p=50% 로 하면 테스트하는 동안에는 하나의 뉴런이 훈련 때보다 두 배 많은 입력 뉴런과 연결된다. 이 점을 보상하기 위해 훈련하고 나서 각 뉴런의 연결 가중치에 0.5를 곱할 필요가 있다. 그렇지 않으면 각 뉴런이 훈련한 것보다 거의 두배 많은 입력 신호를 받기 때문에 잘 동작하지 않을 것이다. 이것을 일반화하면 훈련이 끝난 뒤 각 입력의 연결 가중치에 보존 확률을 곱하거나 훈련하는 동안 각 뉴런의 출력을 보존 확률로 나누어야 한다. Keras에서는 keras.layers.Dropout 층을 사용하여 구현한다.
몬테 카를로 드롭아웃
몬테 카를로 드롭아웃은 기존의 드롭아웃을 이용해 훈련된 모델을 테스트시에도 드롭아웃을 적용시켜 여러번 추정하여 불확실성을 측정하는 기법이다. 훈련된 드롭아웃 모델을 재훈련하거나 전혀 수정하지 않고 쉬운 구현으로 성능을 크게 향상시킬 수 있으며 훈련하는 동안은 일반적인 드롭아웃이므로 규제처럼 작동한다. Dropout 층을 활성화할 시에 training=True로 지정해주고 테스트 세트에서 다수의 예측을 만들어 쌓아 첫 번째 차원을 기준으로 평균 내어 구현한다.
지금까지 과대적합 문제를 해결하는 방법에 대해 정리해보았다. 이제부터는 예제를 통해 직접 DNN으로 예측하는 실습을 해보자.
DNN 실습
XAIOps에서는 모든 데이터가 timeseries 데이터이다. 앞서 언급했듯이 부하예측에 DNN 알고리즘이 사용되고 있다. DNN 실습을 통해 지금까지 공부한 인공 신경망과 DNN에 대해 정리해보고 실제 timeseries 데이터로 예측하는 모델을 구현해 보면 XAIOps에 대해 이해를 잘 할 수 있을 것이다. 데이터는 https://machinelearningmastery.com/time-series-datasets-for-machine-learning/ 에서 'Minimum Daily Temperatures' 데이터를 사용하였다.
필요한 라이브러리 import
import numpy as np
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler데이터 로드
df = pd.read_csv('./dataset/public_data/daily-min-temperatures.csv')
df.head(20)
사용할 데이터를 로드 해준 뒤 해당 DataFrame을 바로 사용하기 전, 처음 n개의 row를 보여주는 head 함수를 사용하여 로드한 데이터의 형태를 확인한다.
Plot 그리기
df.plot(figsize=(40, 12))
해당 DataFrame에서 학습하고자 하는 feature가 특정 패턴을 보이는 지 확인하기 위해
plot 함수를 사용하여 시간에 따른 값의 변화를 확인한다.
Window_size, output_size 설정
window_size = 10
output_size = 5DataFrame으로부터 데이터를 그대로 사용하지 않고 time-series의 성격이 반영된 sequence 데이터셋으로 재생성 후 모델을 학습시켜야 한다. 이를 위해 상수 값을 선언한다. 모델의 목적은 과거의 sequence를 통해 미래의 sequence를 예측하는 것이기 때문에 sequence 데이터를 생성할 때 필요한 것은, 과거 시점과 미래 시점에서 각각 활용할 특정 길이이다. 그래서 과거 시점에 해당하는 길이를 window_size, 미래 시점은 output_size로 하여 각각 10과 5로 하여 이전 10분의 패턴을 통해 미래 5분의 패턴을 예측한다.
Sequence 데이터셋 생성
scaler = StandardScaler()
data = scaler.fit_transform(df['Temp'].values.reshape(-1, 1)).reshape(-1)
x_data, y_data = [], []
for i in range(df.shape[0] - window_size - output_size + 1):
x_data.append(data[i : i+window_size])
y_data.append(data[i+window_size : i+window_szie+output_size])
x_data, y_data = np.array(x_data), np.array(y_data)
x_data.shape, y_data.shape
정확한 예측을 위해 데이터를 스케일링하고, 앞서 설정한 window_size와 output_size를 활용하여 데이터를 Sliding하며 Sequence 데이터셋을 생성한다.
학습 데이터(train data)와 테스트 데이터(test data) 분리
x_train, x_test = train_test_split(x_data, test_size=0.2, shuffle=False)
y_train, y_test = train_test_split(y_data, test_size=0.2, shuffle=False)학습과 검증 및 테스트에 사용할 데이터를 분리하기 위해 train_test_split( ) 함수를 이용하여 두 데이터를 train과 test로 분리한다. 이 때, 보통 test set의 비율은 20%로 한다.
모델 만들기
inp = Input(shape=(window_size,))
hidden = Dense(64, activation='relu')(inp)
hidden = Dense(32, activation='relu')(hidden)
hidden = Dense(16, activation='relu')(hidden)
out = Dense(output_size)(hidden)
model = Model(inp, out)첫 번쨰 라인에서 입력 개수가 Window_size인 입력층을 만든다. 이후 각각 64, 32, 16개의 뉴런을 가진 은닉층을 쌓아준다. 이 때, 활성화 함수를 지정해줘야 하는데 ReLU 함수로 지정해주었다. Output_size로 출력층을 만들어 준뒤 모델을 만든다.
model.summary()
summary( ) 함수를 통해 만들어진 모델 구조를 확인할 수 있다.
모델 컴파일
model.compile(optimizer='adam', loss='mse')모델을 만든 뒤 compile( ) 메서드를 호출하여 사용할 손실 함수와 옵티마이저를 지정해준다. 이 예제에서는 Adam 옵티마이저를 사용했고 손실함수는 MSE로 지정하였다.
모델 훈련
hist = model.fit(x_train, y_train, batch_size=32, epochs=50, validation_date=(x_test, y_test))
model.fit( ) 하여 모델을 훈련시켜준다. 여기서 배치 사이즈와 반복 횟수를 지정하는데 배치사이즈는 32, 반복횟수는 50으로 해주었다. 배치 크기에 대해 잠시 언급하겠다. 배치 크기는 모델 성능과 훈련 시간에 큰 영향을 미칠 수 있다. 큰 배치 크기를 사용하는 것의 장점은 GPU와 같은 하드웨어 가속기를 효율적으로 활용할 수 있다는 점이다. 이로 인해 초당 더 많은 샘플을 처리할 수 있다. 하지만 실전에서 큰 배치를 사용하면 특히 훈련 초기에 종종 불안정하게 훈련된다. 그래서 보통 32까지를 많이 사용한다.
결과 확인
plt.figure(figsize=20, 8))
plt.plot(np.arange(y_data.shape[0]), y_data[:, 0], color='skyblue', zorder=0)
plt.plot(np.arange(y_train.shape[0], y_data.shape[0]), model.predict(x_test, batch_size=128)[:, 0]. color='orange', zorder=1)
plt.axvline(y_train.shape[0], color='red')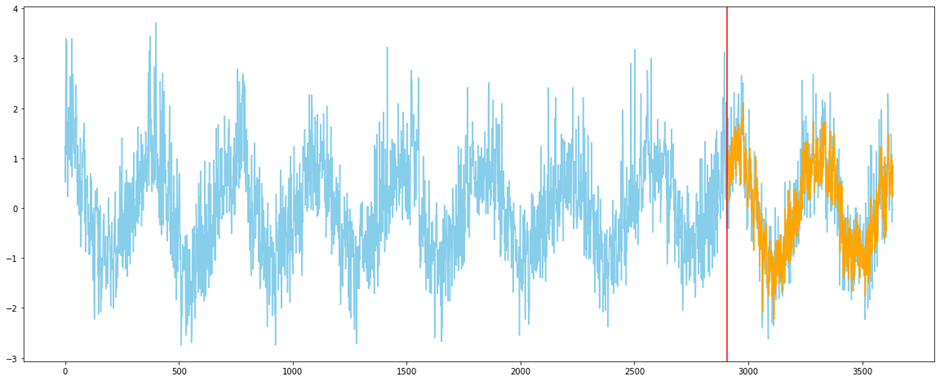
빨간 경계선을 기준으로 모델이 학습한 데이터(좌측)와 모델의 예측 값과 그에 해당하는 데이터(우측)을 그래프로 확인한 결과이다.
plt.figure(figsize=(20, 8))
plt.plot(y_test[:, 0], color='skyblue', zorder=0)
plt.plot(model.predict(x_test, batch_size=128)[:, 0], color='orange', zorder=1)
plt.title(f"t+1 prediction")
plt.show()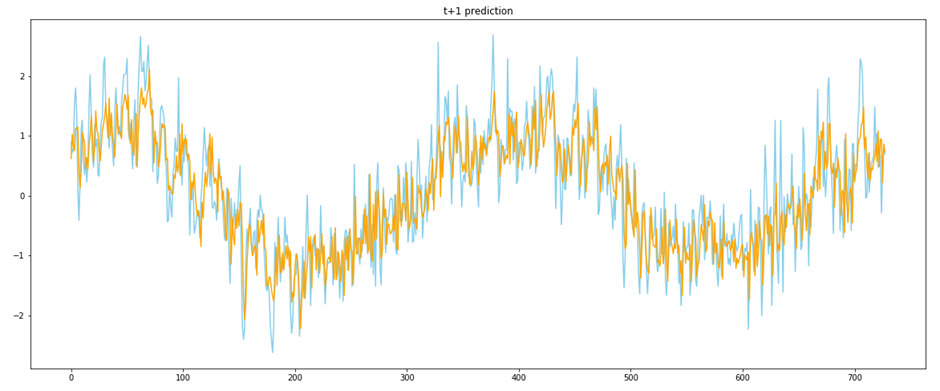
테스트 데이터에 대하여 모델이 1분 뒤의 시점에 대한 예측값들과 그에 대응하는 실제 값을 비교한 그래프이다. 그래프를 보면 실제값과 예측값이 비슷한 것을 확인할 수 있다.
여기까지 인공신경망의 구조와 원리, 활성화 함수, 고속옵티마이저 등 딥 러닝의 전반적인 기초지식에 대해 알아보았고 DNN 예제를 통해 타임 시리즈 데이터로 DNN 모델을 만들고 예측해보았다. 이후에 RNN, AE 등 다양한 딥 러닝 모델을 알아보자.
글 | AI기술연구2팀 김찬경

'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 4-3. RNN (0) | 2023.10.26 |
|---|---|
| Chapter 4-2. 기초 베이지안 통계 (0) | 2023.09.21 |
| Chapter 3-8. 비지도 학습 (0) | 2023.07.26 |
| Chapter 3-7. GAM 이론 및 실습 (0) | 2023.06.29 |
| Chapter 3-6. 차원 축소 (0) | 2023.05.25 |




댓글