
Chapter 3-4. 앙상블과 랜덤 포레스트
이전 회에서 다루었던 과적합 문제를 해결하는 방법 중, 앙상블이 머신러닝에서 많이 사용된다. 이번 회에서는 앙상블의 종류와 앙상블이 어떻게 모델 성능을 향상시키는지 알아보고 랜덤 포레스트에 대해 실습해 볼 것이다.
앙상블이란?
가장 좋은 모델 하나를 사용하는 것보다 여러 모델의 예측을 결합하면 더 좋은 예측 결과를 얻을 수 있다. 앙상블이란 여러 모델을 결합하여 만든 예측기를 뜻한다. 아래 예시로 앙상블을 이해해보자.

위 이미지의 5개 모델은 전부 70%의 정확도를 가진다. 5개 모델을 앙상블로 만들었을 때 성능이 얼마나 향상되는지 알아보자. 5개 모델이 예측 결과를 각각 만들었을 때 최종 결과는 5개 모델의 과반수를 따르는게 타당하다. 나올 수 있는 전체 경우의 수는 아래와 같다.
| 경우의 수 | 과반수가 정답인 경우의 수 | |
| 5개 전부다 정답인 경우 | O |  |
| 4개가 정답이고 1개는 오답인 경우 | O |  |
| 3개가 정답이고 2개가 오답인 경우 | O |  |
| 2개가 정답이고 3개가 오답인 경우 | X | |
| 1개가 정답이고 4개가 오답인 경우 | X | |
| 전부 오답인 경우 | X |
과반수를 따랐을 때, 과반수가 정답인 경우의 수를 합산한 확률은 아래와 같이 나타난다.

위처럼 단순히 예측한 결과의 과반수를 골랐을 뿐인데 예측 정확도가 70%에서 83%로 향상된 것을 확인할 수 있다. 앙상블은 모델이 독립적일 때 뛰어난 성능을 발휘한다. 따라서 앙상블도 모델이 독립적으로 만들어질 수 있도록 다양한 방법이 존재한다. 다음은 앙상블을 만드는 방법 중 배깅, 페이스팅, 그레디언트 부스팅에 대해 알아보자.
배깅이란?
배깅(Bagging)은 학습 데이터셋을 샘플링(Sampling)할 때 중복을 허용하는 방식을 말한다. 아래 이미지를 보면 훈련세트를 무작위로 샘플링하고 각기 다른 예측기로 학습하였는데, 학습에 사용된 4개의 샘플링 데이터엔 중복된 데이터가 존재할 수 있다. 풀려는 문제가 분류라면 예측기 결과들의 최빈값으로 나타내고 회귀인 경우에는 예측기들의 평균으로 계산한다. 또한, 배깅 방식으로 예측기를 훈련시키면 각 예측기는 훈련 샘플의 일부만 샘플링된다. 따라서 예측기마다 각각 다른 out of bag(oob) 샘플이 발생할 수 있는데, 이렇게 남겨진 oob 샘플은 학습에 사용하지 않고 모델 성능 평가에 사용할 수 있다.

아래 이미지는 배깅을 사용하여 학습시키고 최빈값으로 결과를 취합했을 때의 성능을 시각화한 자료이다.

하나의 결정트리를 사용했을 때는 이전 장에서 다루었던 결정트리의 과적합 문제가 크게 나타나는 것을 확인할 수 있다. 반면 배깅을 사용한 결정트리는 과적합이 줄어들고 일반화된 형태로 모델이 학습됨을 확인할 수 있다.
페이스팅이란?
페이스팅은 배깅과는 다르게 중복을 허용하지 않는 샘플링 방식을 말한다. 데이터셋을 나눌 때, 중복된 데이터가 들어가지 않고 샘플링되어 알고리즘에 학습된다.
그레디언드 부스팅이란?
부스팅이란 약한 예측기를 여러 개 연결하여 강한 예측기를 만드는 방법을 말한다. 그 중 그레디언트 부스팅은 이전 예측기가 제대로 학습하지 못한 잔여오차를 다음 예측기가 학습하는 방식이다. 데이터는 동일하지만 이전 예측기의 잔여오차에 대해 다음 예측기가 학습하면서 학습하기 어려운 데이터에 효과적으로 학습하게 된다. 다음은 그레디언트 부스팅으로 잔여 오차를 학습하며 예측기 성능이 향상되는 이미지이다.

이미지내 맨 위 예측기는 데이터셋에 대해 학습하고, 두 번째 예측기는 첫 번째 예측기가 틀린 오차에 대해 학습하고 있다. 마지막 예측기는 두 번째 예측기의 오차에 대해 학습한다. 이렇게 모든 예측기가 학습되었다면 예측기들의 결과를 합산한다.
랜덤포레스트란?
랜덤포레스트란 다수의 결정 트리로부터 분류 결과를 취합해서 예측하는 앙상블 모델이다.
sklearn 라이브러리를 사용하여 랜덤포레스트가 어떻게 학습하고 어떤 형태로 결과가 나타나는지 알아보자.
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
model = RandomForestClassifier(max_depth=3,n_estimators=3)
# sklearn에서 제공하는 iris 데이터를 가져온다.
iris = load_iris()
# 가져온 데이터에서 X만 추출한다.
x = iris.data[:,2:]
# 학습에서 사용한 x지표 이름 -> ['petal length (cm)', 'petal width (cm)']
print(iris.feature_names[2:])
# 가져온 데이터에서 y만 추출한다.
y = iris.target
model.fit(x,y)아래 이미지는 위 코드로 학습한 랜덤포레스트를 나타낸 모습이다. parameter를 max_depth=3, n_estimators=3으로 설정하였기에 총 3개의 결정트리가 각각 3의 depth를 가진다.
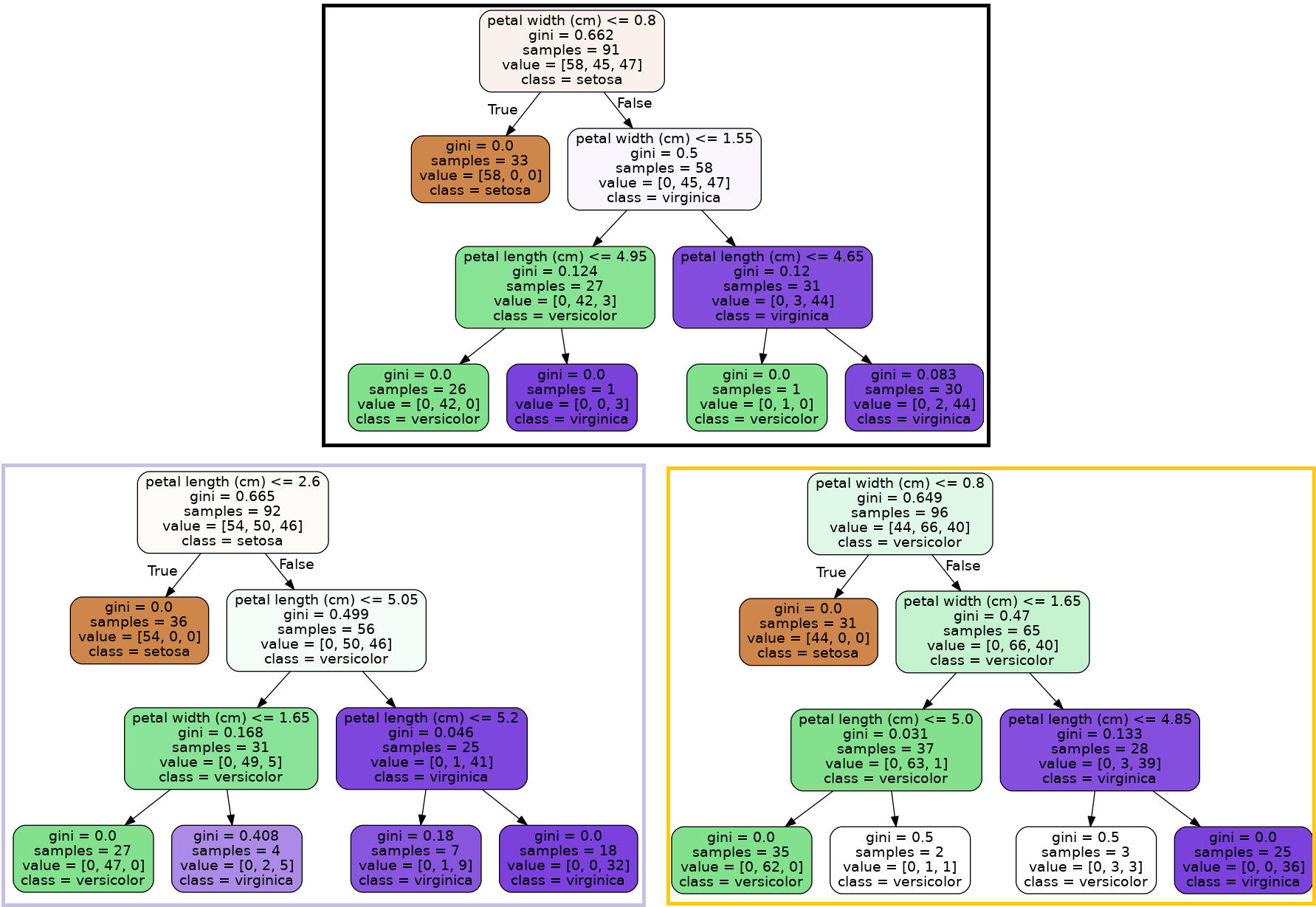

위 이미지를 보면 A 결정트리는 samples의 수 91, B 결정트리는 samples의 수 92, C 결정트리는 samples의 수 96개를 가진 것을 확인할 수 있다. 각 결정트리마다 samples의 수와 value가 다르고 그에 따라 최종 노드가 다른 것을 확인할 수 있다. 이렇게 세 개의 결정트리 결과를 합쳐서 최종 예측으로 사용한다.

글 | AI기술연구팀 김상일
'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 3-6. 차원 축소 (0) | 2023.05.25 |
|---|---|
| Chapter 3-5. 서포트 벡터 머신 (Support Vector Machine) (0) | 2023.04.27 |
| Chapter 3-3. 결정 트리 (0) | 2023.02.22 |
| Chapter 3-2. 모델 훈련 (0) | 2023.01.19 |
| Chapter 3. 머신러닝 (0) | 2022.11.23 |




댓글