
Part.3 Druid Tuning: 제한된 자원속에서 카프카 스트림으로부터 데이터 수집하는 기능(성능)의 최적화
Part.1 Apache Druid란 (링크)
Part.2 Druid Operator: 드루이드 오퍼레이터 도입으로 드루이드 설치부터 관리까지의 과정 개선 (링크)
Part.3 Druid Tuning: 제한된 자원속에서 카프카 스트림으로부터 데이터 수집하는 기능(성능)의 최적화
Part.4 Druid Tiering: 데이터가 조회되는 빈도 기준으로 데이터를 구분
Part.5 Druid without Middle Manager (MM less): k8s 리소스(파드)를 사용한 드루이드 태스크 관리 개선
Kafka로부터 데이터 수집 후 데이터 처리 방법
드루이드에서는 스트리밍 데이터와 배치성 데이터를 처리하는 기능을 제공합니다. 이 중, 스트리밍 데이터를 제공하는 Kafka로부터 데이터를 수집 후 드루이드에서 어떻게 처리하는지 알아보겠습니다.
1) Kafka로부터 데이터 수집
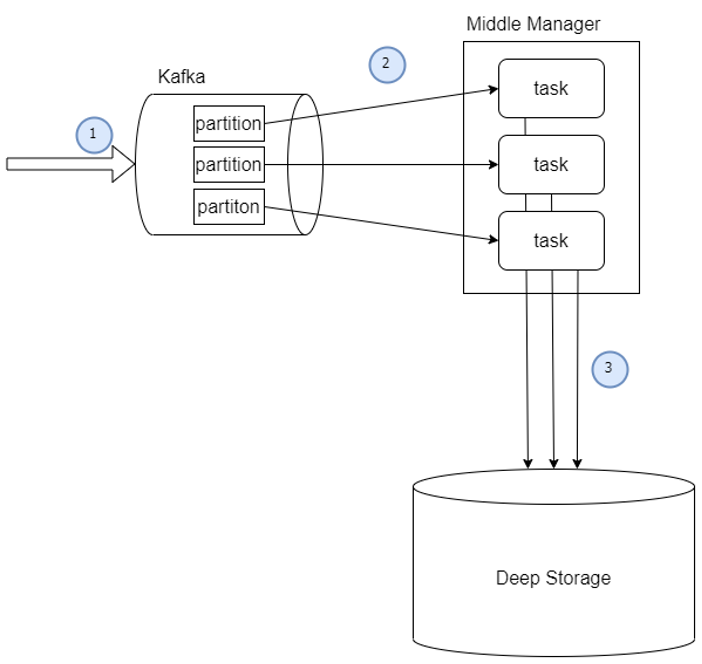
- 카프카에 데이터를 produce 합니다.
- Druid의 MiddleManager는 peon이라는 task를 생성하여 Kafka로부터 데이터를 consume 합니다. 이 때, task는 partition의 수 비율에 맞춰 생성하는 것을 권장합니다. (ex: 1:1, 2:1)
- 수집이 완료되거나 설정을 통해 일정량이 되면 데이터를 Deep Storage로 전송합니다.
2) 수집된 데이터가 처리되는 방법

- 카프카로부터 데이터를 consume 합니다. Consume된 데이터는 각 task 별 메모리에 저장합니다.
- 수집된 데이터의 크기가 일정량을 넘으면 메모리에서 file로 생성하여 저장합니다.
- 일정량의 데이터 또는 시간이 지나게 될 경우 해당 데이터를 Deep Storage로 전송합니다.
테스트에 사용된 자원환경
클러스터링 된 환경 속에서 드루이드가 권장하는 사양은 아래의 표에 있으며 자세한 사항은 공식문서에서 확인할 수 있습니다.(링크)
| Server | Service Type | vCPU | RAM | Disk |
| Data Server | Historical Middle Manager |
16 | 122 | 2 * 2TB SSD |
| Master Server | Coordinator Overlord |
8 | 32 | - |
| Query Server | Broker Router |
8 | 32 | - |
이번 테스트에서는 데이터를 수집하는 환경이 제한적일 경우를 가정하여 진행하도록 하겠습니다. 자세한 환경은 다음과 같습니다.
| Server | Service Type | vCPU | RAM | Disk |
| Data Server | Historical Middle Manager |
16 | 64 | 1.5TB HDD |
| Master Server | Coordinator Overlord |
4 | 16 | - |
| Query Server | Broker Router |
8 | 32 | - |
필요한 설정
제한된 환경에서 테스트를 하기 위해서는 드루이드의 수집 구조를 보다 깊게 파악해야 했으며 설정 값을 통해 데이터를 직접 조작하는 과정이 필요합니다.
1) Threads / Buffer
Threads는 쿼리 결과를 계산하는데 주로 사용하는 쓰레드 풀의 크기를 제어합니다. Buffers는 Thread에 할당된 off-heap 크기를 제어하는데 사용됩니다.
2) Heap Memory / Direct Memory
드루이드가 동작하기 전 Heap Memory와 Direct Memory를 지정할 수 있습니다. 드루이드 권장하는 Heap Memory와 Direct Memory의 공식은 공식 문서에서 확인 할 수 있습니다.(링크)
3) Ingestion Configuration
수집 설정은 크게 두 파트로 나눌 수 있습니다.
- 수집된 데이터를 세그먼트로 나눠서 저장합니다.
- 수집 자체를 설정합니다.
먼저, 수집된 데이터를 세그먼트로 나눠서 저장할 때 설정하는 화면입니다.

1. 세그먼트의 세분성을 나타냅니다. 세그먼트 생성할 때 분 / 시간 / 일 / 월 등으로 생성 기준을 정할 수 있습니다. 세그먼트가 저장하는 데이터의 시간 범위를 지정합니다.
예) hour 일 경우, 세그먼트는 한 시간의 데이터를 갖도록 설정됩니다.
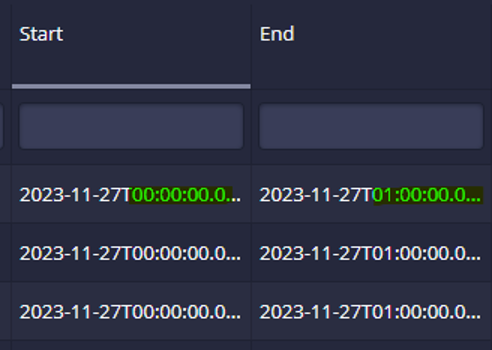
2. 세그먼트 당 최대 데이터의 row 개수를 지정할 수 있습니다. 세그먼트가 해당 설정 만큼의 row를 수집하면 동일한 시간대의 인덱스가 다른 세그먼트가 생성됩니다. 예) 세그먼트 당 최대 데이터의 row 수를 500만개로 지정했을 때, 다음과 같이 동일한 시간대에 0번과 1번의 인덱스로 구분된 세그먼트가 생성된 것을 확인할 수 있습니다.

3. Deep Storage로 전송하기 전에 보유할 수 있는 데이터의 row 최대 개수입니다.
해당 설정에 대한 예시를 들어보겠습니다.
Max rows per segment: 5,000,000
Max total rows: 20,000,000
데이터를 수집중인 세그먼트가 5개인 상황을 가정해보겠습니다. 각 세그먼트가 400만개, 450만개, 450만개, 400만개, 300만개를 수집한 상태일 경우 Max rows per segment보다는 적지만 총 합이 Max total rows이기 때문에 Deep storage로 전송합니다.
수집에 관련된 기능을 튜닝할 수 있습니다. 이 중에서 데이터 수집을 보다 직접적으로 조작할 수 있는 설정은 다음과 같습니다.

| 순서 | 설정 | 설명 |
| 1 | Max rows in memory | 수집된 데이터의 rows수가 메모리에 얼마나 저장할 지 설정할 수 있습니다. |
| 2 | Max bytes in memory | 수집된 데이터의 합계가 메모리에 얼마나 저장할 지 설정할 수 있습니다. |
| 3 | Intermediate persist period | 메모리에 적재된 데이터를 일정 시간마다 파일로 내려받는 주기를 설정합니다. |
| 4 | Intermediate handoff period | 적재된 파일을 일정 시간마다 Deep Storage로 전송하는 주기를 설정합니다. |
이러한 설정들은 수집구조에서 다음과 같이 영향을 미칩니다.

Middle Manager에 할당할 수 있는 자원은 한정되어 있으며, 그 안에서 Task에게 자원을 할당하게 됩니다.
64GiB 중 노드의 기본 사용량과 기타 서비스 사용량을 제외 후 약 60GiB를 할 수 있습니다. Task 하나 당 heap 1GiB, Direct Memory 1GiB로 약 2GiB를 소모하는 것을 알 수 있습니다. 따라서 메모리 사용량으로 계산했을 때, MiddleManager 하나 당 약 30개의 Task를 운용할 수 있습니다.
Task의 메모리 Heap 1GiB, Direct Memory 1GiB를 전부 수집용도로 사용할 수는 없습니다. Druid는 실시간 기반으로 수집된 데이터를 바로 사용할 수 있도록 설계되어 있어, Task에서도 데이터조회를 위해 메모리가 사용됩니다. 따라서 50:50 비율로 메모리를 사용한다고 가정하면 500MiB/500MiB 정도로 계산합니다. 해당 사실로 아래의 내용을 추론할 수 있습니다.
- 적정량 500MiB 최대 1GiB를 넘어갈 경우 Task는 OOM이 발생하여 기능동작을 중단하게 됩니다.
- 50:50 비율 기준으로 봤을 때 500MiB 근처에 도달했을 때 메모리 또는 파일을 해소해줄 경우 안정적으로 수집을 유지할 수 있습니다.
테스트 결과
테스트 시나리오는 다음과 같습니다.
- 초당 약 45,000건의 데이터가 카프카로부터 consume
- 카프카의 파티션은 12개이며, 자원의 한계로 인해 1:2 비율로 Task는 6개
- 데이터 조회 없이 수집만 테스트 하기 위해서 Task의 메모리를 512MiB / 512MiB로 띄울 수 있도록 설정

테스트 시나리오 별로 알아낼 수 있는 사실은 다음과 같습니다.
- 한정된 메모리에서 default값으로는 OOM 발생이 일어난다.
- 중간에 메모리와 디스크를 해소하는 주기가 너무 잦을 경우 같은 세분성을 가진 세그먼트가 너무 많이 생성된다.
- Heap Size > max bytes in memory로 해야 OOM을 방지할 수 있다.
- 데이터 하나 당 bytes 수를 계산하여 Heap Size를 안넘게 설정해야 OOM을 방지 할 수 있다.
여기까지 카프카로부터 데이터 수집 방법을 알아보고 튜닝할 수 있는 부분에 대해 소개했습니다.
카프카에서 데이터를 수집 중이거나 자원 문제를 겪고 있다면, 해당 방법을 고려해 보시는 것을 추천 드립니다.
글 | 통합개발본부 플랫폼3팀 윤혁준님, 박준수님

'엑셈 경쟁력 > Apache Druid가 궁금하면 드루와요' 카테고리의 다른 글
| 궁금하면 드루와요 | Druid without Middle Manager (0) | 2024.01.25 |
|---|---|
| 궁금하면 드루와요 | Druid Tiering (0) | 2023.12.27 |
| 궁금하면 드루와요 | Druid Operator (0) | 2023.10.26 |
| 궁금하면 드루와요 | Apache Druid란 (0) | 2023.09.21 |




댓글