
아파치 드루이드는 대규모 데이터를 분석, 저장할 수 있는 도구입니다. 저희는 k8s 환경에서 드루이드를 운영하고 있으며, 카프카를 연계해 데이터를 수집하고 있습니다. 직접 운영하며 사용한 방법과 수집 구조, 한정된 자원 속에서 수집 성능을 개선한 경험에 대해 이야기를 나누고자 합니다. k8s 환경에서 드루이드를 운영하는 사람, 또 운영하고자 하는 사람, 드루이드에서 Kafka로부터 데이터 수집 성능을 개선하려는 사람들과 함께 소통하고 싶습니다.
총 5파트로 나누어, 이번달에는 아파치 드루이드의 기본 개념을 알아보겠습니다.
Part.1 Apache Druid란?
Part.2 Druid Operator: 드루이드 오퍼레이터 도입으로 드루이드 설치부터 관리까지의 과정 개선
Part.3 Druid Tuning: 제한된 자원속에서 카프카 스트림으로부터 데이터 수집하는 기능(성능)의 최적화
Part.4 Druid Tiering: 데이터가 조회되는 빈도 기준으로 데이터를 구분
Part.5 Druid without Middle Manager (MM less): k8s 리소스(파드)를 사용한 드루이드 태스크 관리 개선
Apache Druid란?
아파치 드루이드는 실시간 데이터 분석을 하는 OLAP DW(대용량 데이터를 다차원 분석을 할 때 속도를 높일 목적으로 설계된 데이터베이스)로, 실시간, 시계열 DB 개념이 결합된 DB입니다. 드루이드는 실시간 수집, 빠른 쿼리 성능, 높은 가동 시간이 중요한 작업에 사용되고 있습니다.
드루이드의 시작은 온라인 광고시스템에서 Clickstream 데이터를 수집하기 위해 만들어진 DB이기 때문에 데이터를 수집하면서 조회하는 성능은 뛰어나지만, 트랜잭션에 관련된 행위를 제공하지는 않습니다. 만약 데이터를 삭제하고 싶을 경우 시간 단위로 저장된 Segment를 삭제할 수 있습니다. 드루이드는 실시간으로 수집되는 데이터를 바로 저장할 수 있고, 저장하기 전에 특정 칼럼을 기준으로 집계를 하여 선택적으로 저장을 하는 기능을 제공해 주는데 이를 Rollup이라고 합니다.
드루이드 기본 기능과 사용되는 분야
주요 기능
- 대규모 병렬 처리
- 실시간 / 배치 처리
- 자가 복구, 밸런싱, 간편 운영
- 시간 기반 파티셔닝
응용 분야
- Web이나 Mobile App에서 수집되는 Clickstream 분석
- 네트워크 성능 모니터링, 네트워크 원격 분석
- 서버 메트릭 정보 수집
- 제조 메트릭 및 공급망 분석
Architecture
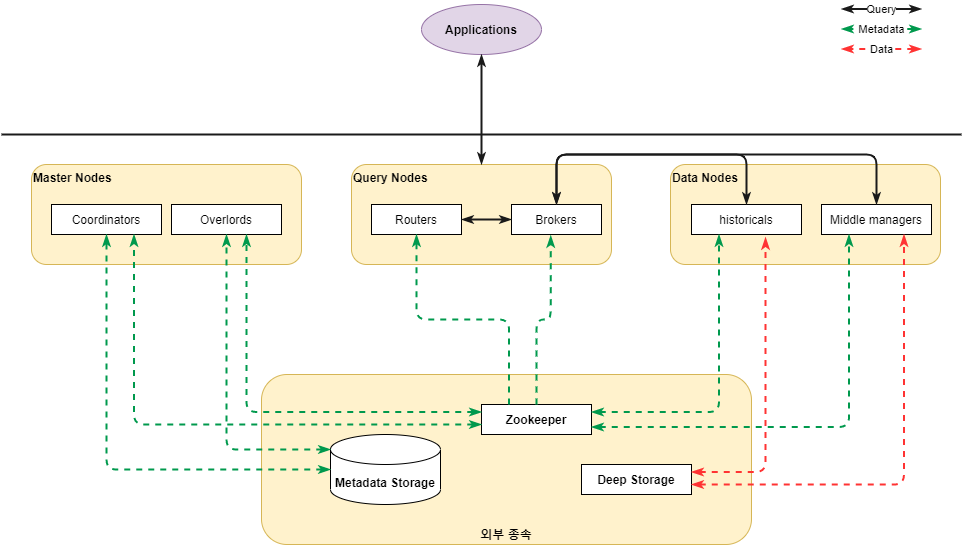
프로세스 종류
- Coordinator
클러스터에서 데이터 가용성을 관리해주는 프로세스로, 세그먼트 관리 및 배포를 담당하며 세그먼트를 load하거나 drop하기 위해 historical 프로세스와 통신함 - Overload
데이터 수집을 하는 workload 할당을 제어하는 프로세스로, task 수락을 하거나 분배, lock 등을 하며 사용자에게 상태 값 전달 - Broker
application에서 요청한 쿼리를 처리 및 라우팅하는 프로세스로, 어떤 프로세스에 어떤 세그먼트가 존재하는지 알고 있으며 쿼리가 올바른 프로세스에 도달하도록 라우팅함 - Router
broker, coordinator, overlord 요청을 routing하는 프로세스로, 프로세스를 구성은 선택 사항 - Historical
실제 Deep Storage 영역에 저장된 데이터에 접근하는 프로세스로, 쿼리 요청 처리 시 필요한 세그먼트 제공 - Middle manager
데이터 수집을 처리하는 프로세스
서버 유형
- Master
coordinator와 overlord 프로세스를 실행하며, 데이터 가용성을 관리 - Query
broker와 router 프로세스를 실행하며, 외부 application의 쿼리를 처리 - Data
historical과 middle manager 프로세스가 실행되며, 쿼리 가능한 모든 데이터를 저장
외부 종속성
- Deep Storage
수집된 데이터가 저장되는 공간으로 HDFS, 아마존 S3, Local Storage로 구성됨 - Metadata Storage
세그먼트 사용 정보, 작업 정보 등 드루이드가 작동되는데 필요한 메타 데이터를 저장하는 공간 - Zookeeper
드루이드 내부 서비스 검색 및 시스템 상태, 설정 정보를 유지 및 관리
데이터 구조
데이터 소스(RDB 기준 Table)는 시간별로 분할되며, 각 시간 범위를 Chunk라고 합니다.
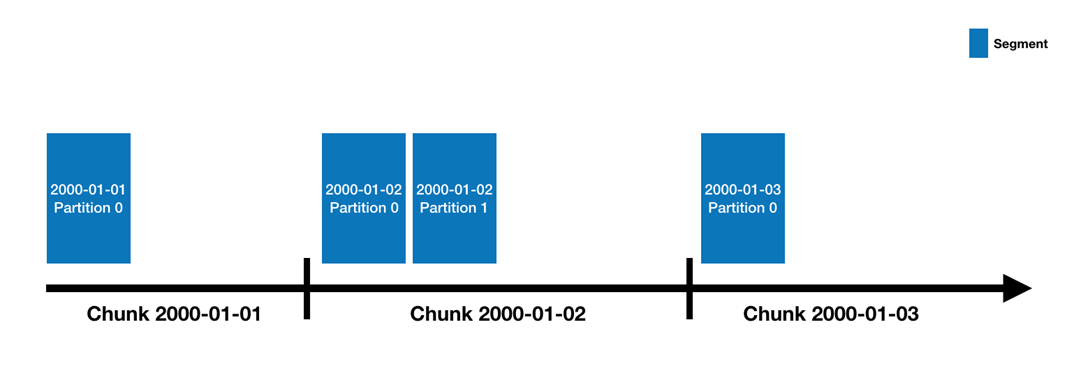
Segment
하나의 데이터 소스는 N개의 세그먼트로 구성되어 있습니다. 데이터와 인덱스를 시간 범위로 구분한 세그먼트에 저장합니다. 세그먼트 파일은 열 구조로 되어 있고, 각 열이 개별적으로 저장되기 때문에 쿼리에 필요한 열만 조회해 쿼리 시간을 줄일 수 있습니다. Timestamp, Dimensions, Metrics 3가지 기본 열 유형을 포함합니다.

Druid Rollup
데이터를 수집하면서 동시에 집계를 하여 데이터를 적재하는 형태입니다. rollup이 이루어진 데이터에 대해 각각의 조회는 불가능하고, 중복이 없는 데이터를 rollup할 경우 성능이 저하됩니다. rollup은 middle manager에서 이루어지기 때문에 middle manager의 리소스가 부족할 경우 rollup 성능이 좋지 않거나 연산이 정확히 안될 수 있습니다.

데이터가 수집되면서 Druid Segments에서 지정된 시간별로 min, max, count, sum을 집계할 수 있습니다.
Rollup의 종류
- Best Effort Rollup
kafka 등 실시간 데이터 수집 시 사용되는 rollup 방식으로, segments task가 종료된 다음 이전 시간의 데이터가 수집될 경우 완벽하게 집계되지 않을 수 있음 - Perfect Rollup
데이터 수집이 완료된 뒤 이루어지는 rollup 방식으로, 리소스를 많이 사용하며 배치 작업으로 데이터를 수집할 경우에 이용 가능
여기까지 드루이드에 대해 간략하게 소개했습니다. 다음 시간에는 데이터세이커 개발 및 운영을 하며 시도했던 드루이드 튜닝이나 실제 클러스터 구성 사례를 이야기하겠습니다.
궁금한 부분이 있으시거나 자세하게 알고 싶은 내용이 있다면 아래 댓글로 문의주세요.
글 | 개발2본부 Backend팀 오승은 / Platform팀 윤혁준, 박준수

'엑셈 경쟁력 > Apache Druid가 궁금하면 드루와요' 카테고리의 다른 글
| 궁금하면 드루와요 | Druid without Middle Manager (0) | 2024.01.25 |
|---|---|
| 궁금하면 드루와요 | Druid Tiering (0) | 2023.12.27 |
| 궁금하면 드루와요 | Druid Tuning (0) | 2023.11.30 |
| 궁금하면 드루와요 | Druid Operator (0) | 2023.10.26 |




댓글