
Part.2 Druid Operator: 드루이드 오퍼레이터 도입으로 드루이드 설치부터 관리까지의 과정 개선
Part.1 Apache Druid란 (링크)
Part.2 Druid Operator: 드루이드 오퍼레이터 도입으로 드루이드 설치부터 관리까지의 과정 개선
Part.3 Druid Tuning: 제한된 자원속에서 카프카 스트림으로부터 데이터 수집하는 기능(성능)의 최적화
Part.4 Druid Tiering: 데이터가 조회되는 빈도 기준으로 데이터를 구분
Part.5 Druid without Middle Manager (MM less): k8s 리소스(파드)를 사용한 드루이드 태스크 관리 개선
Druid Operator란
Druid Operator는 쿠버네티스에서 실행 중인 드루이드 클러스터를 관리하는 도구입니다. 쿠버네티스 오퍼레이터 패턴을 따라 사용자 정의 리소스를 사용하여 요구에 맞게 드루이드 클러스터를 유지합니다.
먼저 드루이드 오퍼레이터가 어떤 방식으로 작동하는지 살펴보겠습니다.
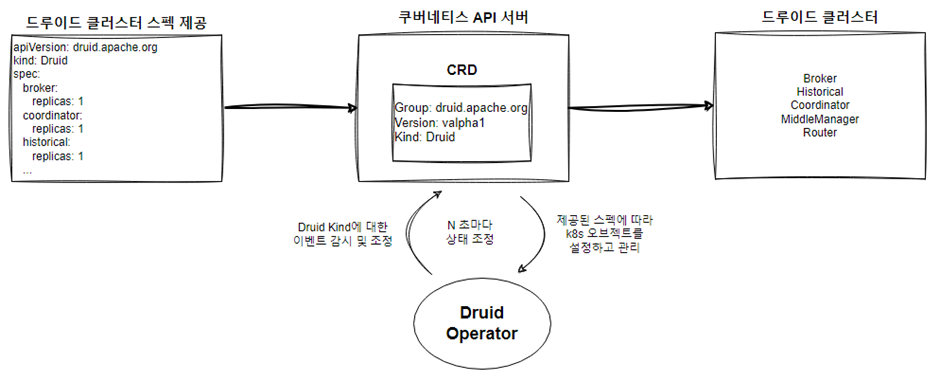
드루이드 오퍼레이터는 Druid라는 별도의 사용자 지정 리소스(CRD)를 생성해 드루이드를 관리합니다.
apiVersion: "druid.apache.org/v1alpha1"
kind: "Druid"
metadata:
name: druid-cluster
namespace: druid
spec:
사용자가 CRD 정의에 맞게 리소스 스펙을 정의하면, 드루이드 오퍼레이터가 작성된 오브젝트(드루이드)를 관리합니다.
오퍼레이트는 주기적으로 사용자가 작성한 리소스 스펙대로 드루이가 실행 중인지 확인하며 상태를 조정합니다.
주요 기능 소개
Rolling Deploy(Update)
드루이드에서 권장하는 서비스 업데이트 순서에 맞게 드루이드 서비스를 재시작합니다.
Orphan pvc 관리
Statefulset이 다운될 경우 파드는 종료되지만, 연관된 PVC를 사용하지 않아 Orphan pvc로 남는 경우 오퍼레이터는 이런 PVC를 삭제합니다.
파드 스케일링
드루이드 노드의 HPA 오토 스케일링을 지원합니다.
드루이드 오퍼레이터 도입 배경
Datasaker는 쿠버네티스상에서 드루이드를 운영 중입니다. 운영하면서 드루이드 클러스터 상태를 관리하는데 어려움이 있었습니다. 개발 계에서 운영 중인 드루이드 클러스터는 여러 테스트를 진행하느라 업데이트가 빈번하게 발생하는데, 매번 각 서비스를 재시작하는데 많은 시간이 소요됐습니다. 드루이드의 서비스는 메타 데이터로 서로의 상태를 공유하기 때문에 드루이드 버전 변경과 같은 업데이트 시 서비스의 재시작 순서를 맞춰야 했습니다.
업데이트 과정을 수동으로 진행하다 보니 소요되는 시간이 클뿐더러 인적 실수로 발생하는 문제들이 있었습니다. 현재 운영 중인 클러스터가 크지 않아 짧은 시간 안에 대처할 수 있었지만, 향후 클러스터 크기가 커질 때의 비용을 생각했을 때 이런 과정을 자동으로 진행해 줄 오퍼레이터의 도입 필요성을 느꼈습니다.
오퍼레이터가 제공하는 여러 기능 중, 저희의 요구를 가장 잘 충족시켜 줄 기능은 Rolling Deploy였습니다. Rolling Deploy에 대한 설명과 오퍼레이터 설치 후 테스트까지의 과정을 설명하겠습니다.
Rolling Deploy(Update)
오퍼레이터를 도입한 이유입니다.
앞서 소개한 대로 Rolling Deploy는 드루이드 클러스터 업데이트 시 드루이드에서 권장하는 업데이트 순서에 맞춰 서비스를 재시작합니다. 권장되는 순서는 Historical -> Overlord -> Middle manager -> Broker -> Coordinator -> Router입니다.
각 드루이드의 서비스는 다른 서비스에 영향을 주기 때문에 실행 중인 태스크와 드루이드 클러스터를 정상적으로 유지하며 업데이트하기 위해서는 권장 순서를 지켜야 합니다.
수동으로 업데이트 진행 시 다음과 같은 불편함이 있습니다.
- 순서에 맞게 한 번에 하나의 서비스만 업데이트해야 하며 업데이트된 서비스가 정상적으로 실행되는 것을 확인 후 다음 서비스를 업데이트해야 합니다.
- 하나의 서비스만 업데이트할 경우, 순서상 해당 서비스의 뒤에 오는 서비스들도 재시작해야 합니다. 예를 들어 broker의 Druid option을 변경해 업데이트하는 경우, 순서 상 뒤에 오는 coordinator와 router도 재시작이 필요합니다.
- (2)의 순서가 틀리면 서비스를 재시작해야 합니다.
오퍼레이터는 순서에 맞게 서비스를 차례대로 업데이트하기 때문에 사용자가 신경 쓸 부분이 줄고 소요 시간 또한 감소합니다. 오퍼레이터 도입 후 최대 20분 걸리던 작업 시간이 5분 이내로 감소했고 업데이트 시 발생하는 각종 인적 실수 또한 사라졌습니다.
오퍼레이터 사용 예시
오퍼레이터 설치부터 드루이드 클러스터 rolling update 예시를 보여드리겠습니다. 쿠버네티스 사용이 어려운 경우 minikube를 이용해 설치할 수 있습니다. 예시는 minikube를 이용했습니다. 필요한 예제 파일은 [여기]에서 찾을 수 있으며, druid operator github에서도 찾을 수 있습니다.
* 참고 사이트: Druid Operator
Helm을 이용한 설치 및 드루이드 배포
* 참고 사이트: Druid Operator Installation
1. Helm repository 추가
Helm으로 설치하기 위해 먼저 레포지토리를 추가합니다.
> helm repo add datainfra https://charts.datainfra.io
정상적으로 레포지토리가 추가됐는지 확인합니다.
> helm repo list
추가된 레포지토리를 이용하도록 업데이트합니다.
> helm update
2. 오퍼레이터 설치
> helm -n druid-operator-system upgrade -i --create-namespace cluster-druid-operator datainfra/druid-operator
Datainfra / druid-operator 차트를 이용해 cluster-druid-operator라는 이름으로 설치하며 druid-operator-system 네임스페이스를 생성합니다.
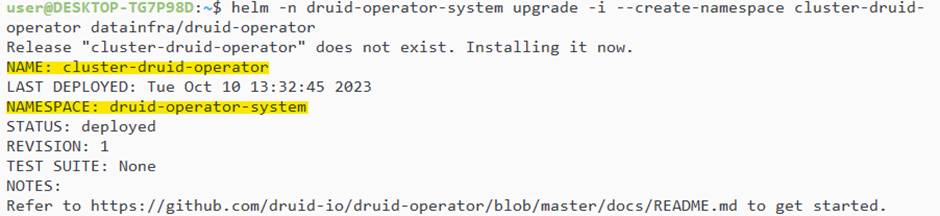
정상적으로 설치됐다면 druid-operator-system 네임스페이스가 생성됩니다.

아래 사진처럼 STATUS가 Running이라면 오퍼레이터는 정상적으로 실행 중입니다.

설치된 오퍼레이터를 이용해 드루이드를 배포해 보겠습니다.
3. namespace 생성
> kubectl create namespace druid
4. zookeeper 배포
> kubectl apply -f zookeeper.yaml* 예제 파일: zookeeper.yaml
5. 드루이드 배포
> kubectl apply -f druid-cluster.yaml*예제 파일: druid-cluster.yaml
6. Router 서비스 생성
> kubectl apply -f router-service.yaml* 예제 파일: router-service.yaml
minikube를 사용 중이시면, 아래 명령어로 서비스에 접근할 수 있도록 추가 설정이 필요합니다.
> minikube -n druid service router-service --url
드루이드 web console 접속: http://127.0.0.1:30020

Rolling Deploy(Update) 테스트
Rolling Update 예시를 위해 드루이드의 버전을 변경하겠습니다.
드루이드 버전 변경 시 모든 서비스의 재시작이 필요하며, 다운 타임을 없애기 위해 드루이드에서 권장하는 순서대로 재시작돼야 합니다.
druid-cluster.yaml의 sepc.image 값을 apache/druid:25.0.0 -> apache/druid:26.0.0으로 변경합니다.
apiVersion: "druid.apache.org/v1alpha1"
kind: "Druid"
metadata:
name: druid-cluster
namespace: druid
spec:
image: apache/druid:26.0.0 # 25.0.0 => 26.0.0 으로 수정
이후 변경 사항을 적용합니다.
> kubectl apply -f druid-cluster.yaml
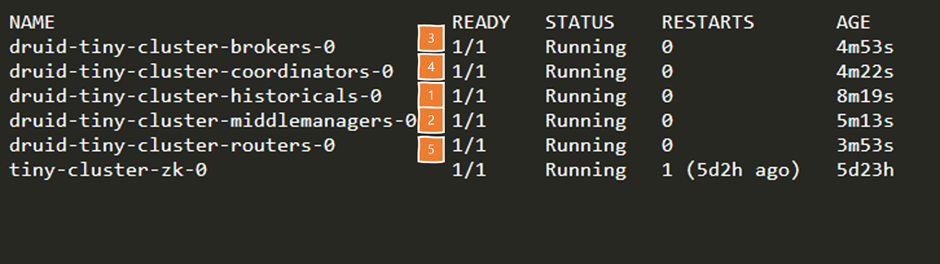
변경 사항이 적용되면 historical 서비스부터 차례대로 재시작됩니다.
서비스 재시작 순서는 다음과 같습니다.
- historical
- middlemanager
- broker
- coordinator
- router
여기까지 드루이드 오퍼레이터를 소개했습니다.
쿠버네티스에서 드루이드 클러스터를 운영 중이거나 계획 중이시라면 오퍼레이터 도입을 고려해 보시는 것을 추천드립니다.
글 | 개발2본부 Platform팀 박준수님, 윤혁준님

'엑셈 경쟁력 > Apache Druid가 궁금하면 드루와요' 카테고리의 다른 글
| 궁금하면 드루와요 | Druid without Middle Manager (0) | 2024.01.25 |
|---|---|
| 궁금하면 드루와요 | Druid Tiering (0) | 2023.12.27 |
| 궁금하면 드루와요 | Druid Tuning (0) | 2023.11.30 |
| 궁금하면 드루와요 | Apache Druid란 (0) | 2023.09.21 |




댓글