
Time Series 머신러닝을 위한 Python 필수 라이브러리, Numpy 1편
머신러닝 알고리즘을 공부하기 앞서, 시계열 데이터를 다루기 위해서 Python 언어의 라이브러리 사용법에 익숙해져야 할 필요가 있다. 이번 챕터에서는 라이브러리를 중점적으로 살펴보며, 여러 실습 예제를 다뤄볼 것이다. Numpy와 Pandas는 큰 규모의 데이터를 탄력적으로 작업할 수 있도록 많은 고성능 도구들을 제공한다. Numpy와 Pandas가 무엇인지 살펴보고, 그 핵심 기능들에 대해 알아보자.
실습을 위한 환경으로는 크게 Jupyter notebook을 직접 구축하여 로컬에서 사용하는 방법과 Google Colab을 사용하는 방법이 있다. 빠른 실습 환경 구축을 위해 Colab을 활용하기를 권장한다.
* Numpy란?
Numerical Python의 줄임말로, 선형대수 기반의 산술 계산을 쉽게 도와주는 라이브러리이다. Numpy를 필수로 사용해야 하는 이유는 대규모 다차원 배열, 수학적, 논리적, 형상 조작, 정렬, 선택, I/O, 이산 푸리에에 대한 신속한 작업 변환, 기본 선형 대수, 기초 통계 연산, 무작위 시뮬레이션 등의 다양한 작업을 지원하고 있기 때문이다.
2-1. 벡터, 행렬 그리고 텐서(Vector, Matrix and Tensor)
머신러닝을 하면 다루게 되는 가장 기본적인 단위는 벡터, 행렬, 텐서이다. 차원이 없는 값을 스칼라(0차원), 스칼라 값들로 구성된 하나의 배열을 벡터(1차원), 1차원인 벡터들로 구성된 하나의 2차원 배열을 행렬(Matrix)이라고 한다. 그리고 그런 행렬들이 합쳐져 하나의 행렬이 되면 우리는 텐서(Tensor)라고 부른다.
사실 우리는 3차원에 살고 있기에, 4차원 이상부터는 머리로 상상하기 어려워진다. 그렇기 때문에 3차원의 텐서를 통해 위 아래로 확장해 가면서 상상해보도록 하자. 3차원을 옆으로 확장하면 4차원, 4차원을 위로 확장하면 5차원, 6차원은 뒤로 확장한 모습이다. 하지만 머신러닝 분야 한정으로 3차원 이상 텐서부터는, 그냥 다차원 행렬 또는 배열로 간주할 수 있다. 주로 3차원 이상을 텐서라고 하지만, 1차원 벡터, 2차원인 행렬의 경우도 텐서라고 표현하기도 한다. 그리고 텐서는 축의 개수(차원 수)와 모양, 데이터 타입을 가지게 되는데 축의 개수(순수 차원 수)만 표현하면 Rank, 각 축에 따른 차원 개수는 Shape으로 표현한다.
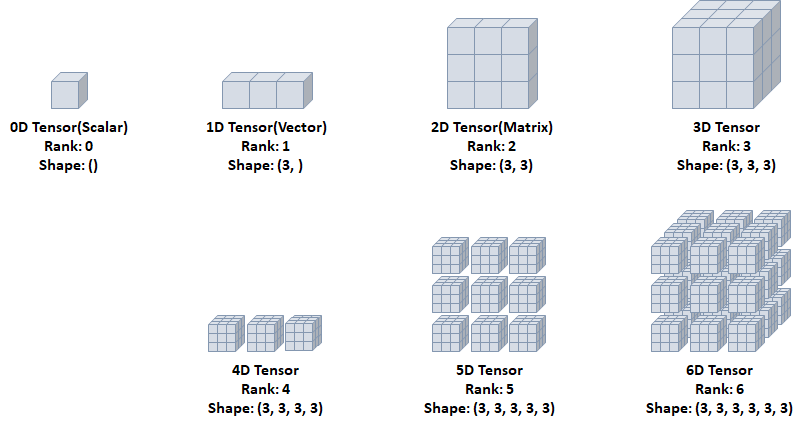
여러 텐서마다 사용되는 방법이 다르다. 그리고 데이터 분석 용도로는 주로 3D 텐서까지만 사용하게 된다. 그렇다면 왜 3D 텐서까지만 사용지에 대해 알아보자.
2D 텐서의 기본 특성은 두 개의 축(x, y)이 존재한다는 것인데, 이는 각 데이터를 특성(Sample feature) 별로 가지고 있을 수 있다. 그리고 일반적인 수치나 통계 데이터셋이 대부분 행렬로 된 구조로 되어있기 때문에, 2D 텐서를 사용하고 있다.

3D 텐서의 경우 2D 텐서를 뒤로 쌓은 마치 큐브(Cube)와 같은 모양으로 세 개의 축이 존재한다. 해당 텐서의 사용 용도는 주로 흑백 이미지나, 시계열 데이터 등의 데이터(주식 가격 데이터셋, 시간에 따른 질병 발병 등)가 존재한다. 이때 시계열에서 사용하기 위해서는 데이터가 연속된 시퀀스 데이터이거나 시간 축이 포함된 데이터여야 하기 때문에 특성은 Features, Timesteps, Samples인 구조를 사용한다.
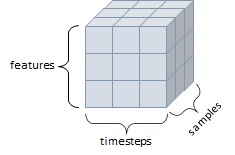
2-2. Python, Numpy 속도비교
Numpy 라이브러리는 기존 Python 내장 함수보다 속도가 빠르다. 궁극적으로 Python은 동작속도가 빠른 언어가 아니다. C언어보다 최대 200배, Java보다 최대 20배 정도 느리다고 한다. Numpy는 이를 보완해서 고성능 퍼포먼스를 낼 수 있게 도와주는 라이브러리이다.
import numpy as np
array = np.random.rand(100000)
%timeit sum(array)
%timeit np.sum(array)
그림 2-2-1 Python, Numpy 단순 속도 비교
단순 시간만 비교를 해봐도 속도 차이가 수 백배 나는 것을 알 수 있다. Python이 왜 느린가를 보면, 같은 데이터를 표현하더라도 기본 Python에 비해 Numpy가 비교적 빠른 연산을 지원하고 메모리를 효율적으로 사용하기 때문이다. C언어는 변수에 값을 할당할 때 자료형을 명시해 주고 변수에 접근할 때 타입을 알기 때문에 바로 접근이 가능하지만, Python은 사용자가 자료형을 지정해 주지 않아도 알아서 할당을 하게 되는 구조이다. 이는 변수에 접근할 때마다 어떤 값이 타입인지 매번 체크를 해야 하기 때문에 Python이 느릴 수밖에 없다. 결론적으로 Numpy는 내부적으로 Python에서 느리게 하는 동작들을 C로 구현함으로써 최적화 했기 때문에 수 십에서 수 백배의 성능 향상을 보여줄 수 있다. 그렇기 때문에 같은 동작을 하는 것이라면 Python 기본으로 제공하는 함수보다 Numpy를 최대한 활용하도록 하자.
2-3. Ndarray 생성하기
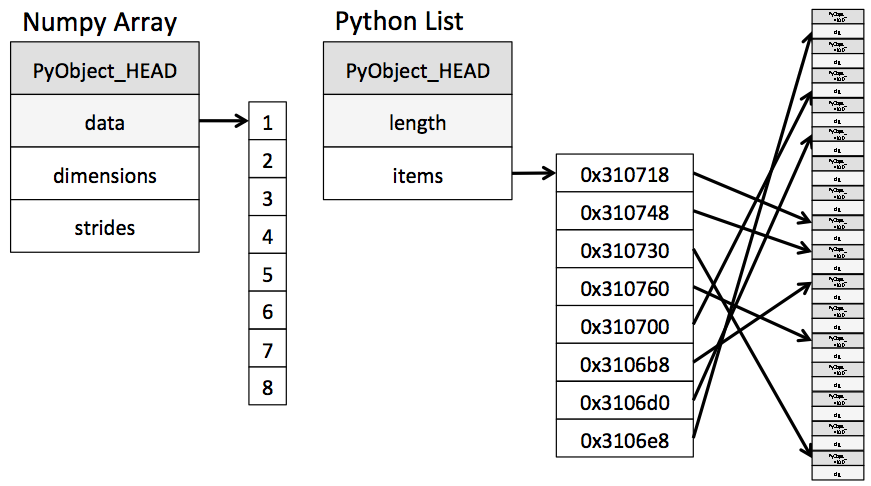
Numpy의 자료형은 Ndarray로 배열 연산을 빠르게 하기 위해 개발되었다. Python 리스트와 Ndarray는 유연성과 효율성 측면에서 차이가 있다. Python 리스트의 경우 서로 다른 자료형을 담을 수 있어 유연성이 높은 반면, 각 요소에 대한 정보를 전부 담아야 되기 때문에 차지하는 메모리의 크기, 반복문 사용이 필수적이다. 이 때문에 효율이 떨어질 수밖에 없다. Ndarray의 경우 같은 자료형끼리만 연산이 가능하기 때문에 유연성은 떨어질 수 있지만, 모든 요소 정보를 한 번에 저장하고 C로 구현된 알고리즘을 사용하기 때문에 속도가 매우 빠르다. Numpy의 경우 Python에서 제공하는 리스트보다 속도도 빠르고, 배열을 쉽게 만들기 위한 함수들을 제공하고 있다.
2-3-1. Numpy 배열 만드는 방법
Numpy는 리스트를 활용해 배열을 만들 수 있다. 그 외에 Numpy.array() 함수의 인자로 튜플, Ndarray, mat와 같은 array-like 객체들을 전달해 배열을 만들 수도 있다. Numpy.array()로 만들어진 Ndarray 객체들은 array로 표현된다. Ndarray는 같은 자료형만으로 구성되므로 arr2, arr3처럼 하나라도 다른 자료형이 들어오게 되면 그 중에서 제일 큰 자료형으로 정의된다.
arr1 = np.array([1,2,3,4,5])
arr2 = np.array([1.1,2,3,4,5])
arr3 = np.array([1,2,3,4,5], dtype = float)
print(arr1, arr1.dtype)
print(arr2, arr2.dtype)
print(arr3, arr3.dtype)
그림 2-3-1-1. List로 Numpy 배열 생성 및 타입 확인
2-3-2. Ndarray 자료형, 차원 크기 확인
Numpy는 같은 자료형끼리만 연산이 가능하기 때문에 해당 배열의 자료형을 확인할 필요가 있다. dtype을 통해 배열 안에 자료형이 무엇인지 알 수 있다.
data = np.random.randn(2,3)
print(data)
print(data.dtype)
print(data.shape)
Out [8]:
그림 2-3-2-1. Numpy 배열 생성 후 자료형 및 형태 확인
추가로 배열을 생성할 때 ndmin을 옵션을 통해 최소 차원을 지정할 수 있다. 그리고 차원 추가가 필요한 때가 있는데 이는 행 벡터를 만들어서 계산을 할 때 축을 맞추기 위함이다.
arr = np.array([1,2,3])
arr2 = np.array([1,2,3], ndmin = 2)
arr3 = np.array([1,2,3], ndmin = 2)
print(arr)
print(arr.shape)
print(arr2)
print(arr2.shape)
print(arr3.T)
[1 2 3]
(3,)
[[1 2 3]]
(1, 3)
[[1]
[2]
[3]]그림 2-3-2-2. 형태, 차원 추가, 전치행렬
배열을 생성할 때 주의할 점이 있다. Np.array의 경우 함수 인자로 스칼라 형태의 값을 전달해 줄 수 있다. 그렇게 되면 ndarray는 0차원이 되며, 모양은 (), 크기는 1이 된다. 리스트로 전해줄 경우 1차원이 되고, 모양은 (1,), 크기는 1이된다. 즉 단순하게 스칼라를 인자로 전달하는 것과, 리스트로 인자를 전달하는 것은 확실하게 구분해야 된다.
arr4 = np.array(10)
arr5 = np.array([10])
print(arr4)
print(arr4.shape)
print(arr5)
print(arr5.shape)
Out [14]:
10
()
[10]
(1,)그림 2-3-2-3. 배열 생성 시 주의할 점
2-3-3. 특정 수로 채워진 배열 만들기
지정된 Shape 및 데이터 유형으로 특정 값으로 채워진 배열을 생성할 수 있다.
- np.zeros(Shape)
In [15]:
arr_zeros = np.zeros((10,2), dtype = int)
print(arr_zeros)
그림 2-3-3-1. 0으로 채워진 크기가(10, 2)인 벡터 생성
- np.ones(Shape)
In [17]:
arr_ones = np.ones((10,2), dtype = int)
print(arr_ones)
Out [19]:
그림 2-3-3-2. 1로 채워진 크기가(10, 2)인 벡터 생성
- np.full(Shape, x)
arr_full = np.full((10,2), 10)
print(arr_full)
Out [22]:
그림 2-3-3-3. 10으로 채워진 크기가(10,2) 벡터 생성
2-3-4. 범위를 지정해서 배열 만들기
for문 순회 상황 등에서 Python Range 함수처럼 특정 수열을 만들고자 할 때 자주 사용된다. Python의 Range, Numpy arange 함수와 사용 방법은 동일하다. 이 함수 또한 차이가 존재하는데, 첫 번째로 range의 경우 정수 단위만 지원하지만, arange의 경우 실수 단위도 표현 가능하다.
print(np.arange(1, 5, 0.5))
Out [24]:
print(range(1, 5, 0.5))
Out [26]:
그림 2-3-4-1. arange와 range의 차이
- np.arange(start, stop, step)
range 함수와 동일하게 작동하면서 Ndarray를 반환한다. start부터 stop까지, step만큼 건너뛴 값으로 이루어진 배열을 반환한다.
arr_arange = (np.arange(0, 10, 2))
arr_arange
- np.linspace(start, stop, num)
arange와는 다르게, start부터 stop까지 num 만큼의 간격을 가지는 요소의 배열을 반환한다.
arr_linspace = np.linspace(0, 10, 5)
arr_linspace
그림 2-3-4-3. linsapce를 이용한 배열 생성
아래는 Numpy 함수들이며, 이외에도 많은 함수들이 존재하고 있다.
| array(list or tuple or like_array) | 배열 생성 |
| asarray(arr) | 배열안에 데이터가 전부 같은 형태인지 확인 |
| copy(arr) | 새로운 주소를 할당하여 복사하려는 배열을 복사 |
| arange(start, stop, step) | 주어진 값 내에서 step의 크기만큼 일정하게 떨어져 있는 숫자들을 array 형태로 반환 |
| linspace(start, stop, num, endpoint, dtype) | 균등한 견격을 둔 시퀀스를 생성한다. |
| meshgrid(*xi, copy =True, sparse = False, indexing= ‘xy’) | 1차원 좌표 배열에서 N차원 직사각형 격자를 만들어 준다. |
| mgrid[start:end, start:end] | 브로드 캐스팅을 위한 차원을 늘린 배열 생성 |
| ogrid[start:end, start:end] | 브로드 캐스팅을 위한 1Xn, nX1 두개의 행렬 생성 |
| diag(v, k]) | 대각 원소 추출하는데 k를 통해 원하는 대각선 |
| diagflat(v, k]) | 평평하게 되어 입력의 k 번째 대각선으로 설정 |
| tri(m,n, k) | mXn 1인 행렬 생성 뒤 크기 k 만큼 삼각형 0행렬로 변경 뒤 생성 |
| vander(x[, N, increasing]) | 방데르몽드 행렬 생성 |
| mat(x) | X를 행렬로 변환 |
| empty(shape, dtype, order) | 초기화 되지 않은 값으로 배열 생성 |
| eye(M, k, dtype) | 2차원 행렬생성 및 대각에 k값인 행렬 생성 |
| ones(shape[, dtype, order, like]) | 1로 채워진 행렬 생성 |
| zeros(shape[, dtype, order, like]) | 0으로 채워진 행렬 생성 |
| full(shape, fill_value[, dtype, order, like]) | 지정된 값으로 행렬 생성 |
Numpy 2편에서는 인덱싱, 슬라이싱, 전치행렬, 산술연산에 대해 알아보자.
Chapter 1. Time Series 머신러닝을 위한 기초 선형대수 및 통계학부터 학습하고 싶다면 여기로!
그림 출처
https://codetorial.net/numpy/basics.html

기획 및 글 | AI 1팀 김기중
'엑셈 경쟁력 > 시계열 데이터처리 AI 알고리즘' 카테고리의 다른 글
| Chapter 2. Pandas 3편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.08.25 |
|---|---|
| Chapter 2. Pandas 2편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.08.25 |
| Chapter 2. Pandas 1편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.08.25 |
| Chapter 2. Numpy 2편 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.07.27 |
| Chapter 1. 기초 선형대수 및 통계학 : Time Series 머신러닝을 위한 Python 필수 라이브러리 (0) | 2022.06.27 |




댓글