

시작하며
앞선 문서를 통해 Page Layout, HOT, Fillfactor, Single-page Vacuuming 등 HOT Update를 이해하기 위해 필요한 개념들에 대해 살펴보았습니다. 본 문서에서는 이러한 개념들을 활용하여 Update가 동작하는 다양한 케이스에 대해 확인해 보도록 하겠습니다.
PostgreSQL의 Update
PostgreSQL에서 Update는 이전 버전(변경 전)의 Tuple을 유지하는 방법을 통해 다중 버전 관리(MVCC)를 구현합니다. 즉 Update가 발생하면 새로운 버전의 Tuple을 생성한 후 이전 버전은 논리적으로 Delete 처리(Tuple을 유효하지 않은 것으로 표시)하는 것으로 대체합니다.
이러한 MVCC 기반의 Update 동작 방식을 수행 대상에 따른 Update 유형으로 분류하면 다음과 같습니다.
Update Case
- 인덱스가 없는 테이블에 대한 Update 수행
- 인덱스에 포함되지 않은 컬럼에 Update 수행
- 인덱스에 포함된 컬럼에 Update 수행
위 Case들은 사실상 Update와 관련해 발생할 수 있는 모든 경우의 수를 나타냅니다. 이들 각각에 대해 동일한 Step을 수행함으로써, Update의 과정 중 발생할 수 있는 페이지의 변화와 이들 사이의 차이점에 대해 살펴보도록 하겠습니다.
또한 이러한 일련의 테스트과정은 HOT Update를 유도하기 위해 아래와 같은 Fillfactor 및 컬럼사이즈로 설정합니다. (*아래 HOT Update 제약 조건 참조)
## 테이블 페이지의 사이즈는 8K (8192 Bytes)
## 최대 4개의 튜플 버전이 하나의 페이지에 존재하도록 컬럼 사이즈 조정
## => 하나의 튜플당 Char(2000), Integer 및 LP 정보를 포함하여 약 2K (2032 Bytes)
## Fillfactor 설정 (60%)
## => Update 이미지 저장을 위한 공간을 예약하고,
## => 3개 버전의 튜플 존재시 Single-page Vacuuming을 트리거 하기 위함
create table tN (c1 char(2000),c2 integer) with (fillfactor=60);📢 HOT Update 제약 조건
① Update 수행 시 테이블의 인덱스가 참조하는 컬럼이 Update 대상이 아니어야 한다.
② Update 이전 버전과 동일한 페이지에 새로운 버전의 Tuple을 저장할 수 있는 공간이 충분하여 Update 전/후 Tuple이 하나의 테이블 페이지에 존재해야 한다.
참고 : Tuple상태 확인을 위해 사용할 Script (HEAP_PAGE & INDEX_PAGE FUNCTION)
## 참고자료 - PostgreSQL 14 Internals by Egor Rogov
## https://postgrespro.com/community/books/internals
## HEAP_PAGE & INDEX_PAGE FUNCTION
create extension pageinspect;
drop function heap_page(text, integer);
create function heap_page(relname text, pageno integer)
returns table( ctid tid,
state text,
xmin text,
xmax text,
hhu text,
hot text,
t_ctid tid )
as $$
select
(pageno, lp)::text::tid as ctid,
case
lp_flags when 0 then 'unused'
when 1 then 'normal'
when 2 then 'redirect to ' || lp_off
when 3 then 'dead'
end as state,
t_xmin || case
when (t_infomask & 256) > 0 then ' c'
when (t_infomask & 512) > 0 then ' a'
else ''
end as xmin,
t_xmax || case
when (t_infomask & 1024) > 0 then ' c'
when (t_infomask & 2048) > 0 then ' a'
else ''
end as xmax,
case
when (t_infomask2 & 16384) > 0 then 't'
end as hhu,
case
when (t_infomask2 & 32768) > 0 then 't'
end as hot,
t_ctid
from
heap_page_items(get_raw_page(relname, pageno))
order by
lp;
$$ language sql;
drop function index_page(text, integer);
CREATE FUNCTION index_page(relname text, pageno integer)
RETURNS TABLE(itemoffset smallint, htid tid)
AS $$
SELECT itemoffset,
htid -- ctid before v.13
FROM bt_page_items(relname,pageno);
$$ LANGUAGE sql;Case 1. 인덱스가 없는 테이블에 대한 Update 수행
우선 인덱스가 없는 테이블에 대한 Update 수행과정에 대해 알아보도록 하겠습니다.
앞서 강조한 MVCC 처리방식에 의하면, 인덱스가 없는 테이블의 Tuple를 Update 하면 우선 해당 Tuple이 저장되어 있는 페이지에 새로운 버전의 Tuple을 생성할 만큼의 Free Space가 존재하는지 확인합니다. 이후 조건 만족 시 새로운 버전의 Tuple을 해당 페이지에 생성합니다.
Case 1은 HOT Update를 위한 제약조건을 충족하므로 Update 최적화가 동작할 텐데, 실제 페이지 내부에 어떤 변화들이 일어나는지 7개의 Step을 통해 확인해 보겠습니다.
1-1. 테스트 테이블 생성
create table t1 (c1 char(2000),c2 integer) with (fillfactor=60);1-2. Insert 수행
insert into t1 values('a',1);
생성한 테이블 t1에 1개의 Tuple을 Insert 하면 페이지 내 LP1(0,1)과 Tuple이 각각 생성됩니다.
1-3. Update 수행
update t1 set c1='b';
update t1 set c1='c';
1번에서 Insert 한 Tuple에 대해 Update를 수행하면, Tuple v1에 대한 새로운 버전 Tuple v2를 생성합니다. 이어서 Update를 수행하면 또 다른 버전인 Tuple v3이 추가로 생성됩니다.
HEAP_PAGE (’T1’, 0)를 통해 해당 페이지의 LP 및 Tuple 상태를 조회해 보면 왼쪽 그림과 같이 후속(이후) 버전에 대한 LP정보를 t_ctid에 저장하여 HOT Chain의 형태를 이루고 있음을 알 수 있습니다. 또한 hhu(HEAP_HOT_UPDATED)와 hot(HEAP_ONLY_TUPLE) 값을 통해 HOT Update 동작을 확인할 수 있습니다.
📢 Script에서 정의하고 위 결과에 출력되는 컬럼 - hhu와 hot는 모두 t_infomask2를 기반으로 하는 HOT Update 관련 플래그 값입니다.
- hhu(HEAP_HOT_UPDATED) : HOT Update가 수행되어 HOT Chain에 포함된 Tuple 중에서 Chain을 통해 연결되는 다음 Tuple이 HOT(Heap-only Tuple)인 경우 해당 플래그로 표시됩니다.
- hot(HEAP_ONLY_TUPLE) : HOT Update를 통해 생성된 Tuple 중에서 해당 Tuple을 가리키는 인덱스가 없는 Tuple인 경우 해당 플래그로 표시됩니다. (이 Tuple들은 인덱스에서 HOT Chain의 Head를 통해서만 간접적으로 Access 할 수 있습니다)
Case1과 같이 인덱스가 하나도 없는 테이블의 경우에는 HOT Chain의 Head가 가리키는 Tuple을 제외한 나머지 Tuple에 대해서 해당 플래그가 표시됩니다.
1-4. Select 수행 ( * Single-page Vacuuming 트리거)
select * from t1;
c1 |c2|
----+--+
c | 1|
t1 테이블을 Select 하여 페이지를 읽을 때, Fillfactor 임계치(60%)를 초과한 상태라면 Single-page Vacuuming이 트리거 됩니다. Single-page Vacuuming이 트리거 되면 Dead Tuple인 Tuple v1과 Tuple v2는 페이지에서 삭제됩니다. 하지만 실제 Dead Tuple(Item)이 제거되는 것과 달리, HOT Chain의 Head인 LP1(0,1)은 유효한 Tuple인 Tuple v3을 찾아갈 수 있도록 LP3으로 Redirection을 추가하며, 불필요해진 LP2는 unused 상태로 변경합니다.
📢 Script에서 정의하고 위 결과에 출력되는 컬럼 - State는 lp_flags 값에 의해 결정되며 normal, dead, redirect, unused 등이 있습니다.
- unused : lp_flags=0, 사용하지 않음 (항상 lp_len=0)
- normal : lp_flags=1, 사용됨 (항상 lp_len>0)
- redirect : lp_flags=2, HOT Redirection (lp_len=0)
- dead : lp_flags=3, 가리키고 있던 Tuple은 제거되었으나, LP는 아직 외부에서 참조되므로 재사용할 수 없음
unused 상태의 LP만 즉시 재사용 가능합니다.
추가적으로 Tuple v3는 Free Space의 마지막 주소로 이동하는데, 이는 물리적 위치의 변경을 요하므로 LP3가 가리키는 Tuple의 Offset 정보가 변경됩니다. 이러한 Tuple의 이동은 Free Space의 단편화(Fragmentation)를 예방하는 효과를 갖습니다.
📢 HOT Update를 통해 생성된 Tuple들은 HOT Chain을 구성하는데, 이때 HOT Chain에 가장 먼저 포함된 LP를 HOT Chain의 Head로 지정합니다. Case 1의 경우, 인덱스가 없는 테이블이므로 인덱스에서 참조되는 값은 아니지만 그 값이 변경되지 않는다는 특징은 그대로 가집니다.
1-5. Update 수행
update t1 set c1='d';
같은 Tuple에 다시 Update를 수행하면 새로운 버전의 Tuple v4를 생성합니다. 이때, Tuple v4를 가리키는 LP는 신규로 할당받지 않으며, unused 상태의 LP2를 재사용합니다. 또한 이전 버전인 Tuple v3의 t_ctid에는 Tuple v4을 가리키는 LP2(0,2) 정보를 저장하여 HOT Chain을 연결합니다.
1-6. 테이블 전체에 대한 VACUUM 수행
vacuum t1;
사용자가 테이블 t1에 대해 Vacuum을 수행하면 Dead Tuple을 제거하고 관련된 LP도 정리합니다. 즉 Vacuum 수행 후, Tuple v3는 제거되며 LP3는 unused 상태가 되어 재사용 가능해집니다.
또한 HOT Chain의 Head가 유효한 Tuple을 가리키도록 Redirection을 LP3에서 LP2로 재설정하며, Tuple v4의 물리적 위치이동을 반영하여 LP2의 Offset값을 변경합니다. (Case 1.4 Single-page Vacuuming과 동일하게 작동)
1-7. Update 수행
update t1 set c1='e';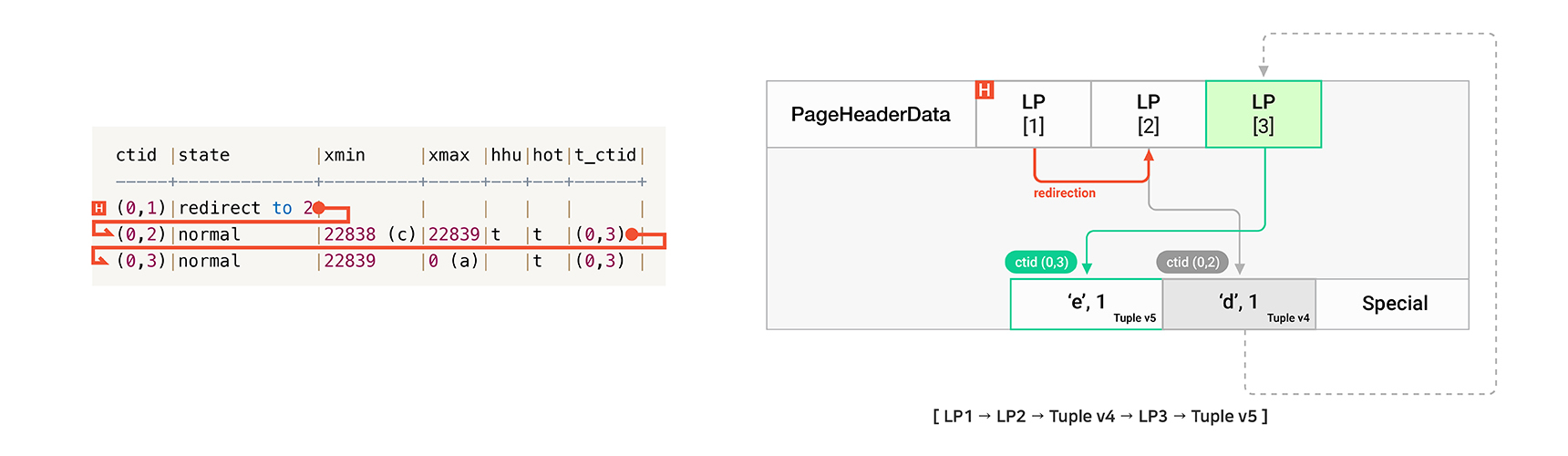
이후 다시 HOT Update가 수행되면, 새로운 버전 Tuple v5를 추가 생성합니다. 해당 페이지에 재사용 가능한 LP가 있다면 재사용하며, 그렇지 않다면 LP도 추가 생성해야 합니다. 위 그림에서는 LP3를 재사용하여 Tuple v5를 가리키는 데 사용하였다는 것을 알 수 있습니다.
Case 2. 인덱스에 포함되지 않은 컬럼에 Update 수행
두 번째로 인덱스에 포함되지 않은 컬럼을 Update 하는 경우에 대해 알아보도록 하겠습니다.
일반적으로, 인덱스가 존재하는 테이블에 Update를 수행하면, 인덱스 엔트리 역시 추가되어야 한다고 생각할 수 있습니다. 하지만 Update 대상컬럼이 인덱스에 포함되지 않았다면, 동일한 키값의 인덱스 엔트리를 생성하기 위해 굳이 인덱스를 추가하거나 변경할 필요는 없습니다.
Case 2는 HOT Update 제약조건을 만족하며, 인덱스 엔트리에 대한 변화가 없으므로, HOT Update가 정상 동작할 것입니다. 이를 Case 1과 비교하여 동작상의 차이점이 존재하는지 동일한 Step을 통해 알아보도록 하겠습니다.
2-1. 테이블 & 인덱스 생성
create table t2 (c1 char(2000),c2 integer) with (fillfactor=60);
create index t2_idx on t2(c2);2-2. Insert 수행
insert into t2 values('a',1);
새로운 Tuple을 Insert 하면 테이블 페이지의 빈 공간에 Tuple을 생성하고 인덱스 페이지에도 해당 Tuple에 대한 키값을 추가합니다.
2-3. Update 수행
update t2 set c1='b';
update t2 set c1='c';
Case 2-2에서 Insert 한 Tuple에 대해 두 번의 Update를 차례로 수행한 후 HEAP_PAGE (’T2’, 0)의 결과를 확인하면, hhu 및 hot값을 통해, HOT Chain이 생성되고 HOT Update가 동작했음을 확인할 수 있습니다.
또한 INDEX_PAGE (’T2_IDX’, 1)의 결과를 통해, 일련의 Update과정이 인덱스 엔트리에 대한 추가 및 변경을 야기하지 않았으며, HOT Chain의 Head인 ctid(0,1)를 참조하고 있음을 알 수 있습니다.
📢 인덱스 페이지에서 HOT Chain의 Head인 LP1을 참조하는 부분만 제외하면, 해당 Case는 Case 1-3 Update 과정과 동일합니다.
2-4. Select 수행 ( * Single-page Vacuuming 트리거)
select * from t2;
c1 |c2|
----+--+
c | 1|
t2 테이블을 Select 하여 페이지를 읽을 때 Fillfactor 임계치를 초과한 상태라면 Single-page Vacuuming이 트리거 됩니다. Single-page Vacuuming과정은 Case 1-4와 동일하며 Dead Tuple 및 LP에 대한 정리 작업을 진행합니다.
다만, HOT Chain의 Head가 동일하게 유지되므로, 이를 가리키는 인덱스 엔트리에 대한 변화가 불필요하다는 점을 유념하시기 바랍니다.
2-5. Update 수행
update t2 set c1='d';
같은 Tuple에 대해 다시 Update가 수행되면 새로운 버전의 Tuple v4를 추가로 생성합니다. Tuple v4를 가리키는 LP는 재사용 가능한 LP2가 있으므로 이를 재사용하며, 이전 버전인 Tuple v3의 t_ctid에는 Tuple v4을 가리키는 LP2(0,2) 정보를 저장합니다.
2-6. 테이블 전체에 대한 VACUUM 수행
vacuum t2;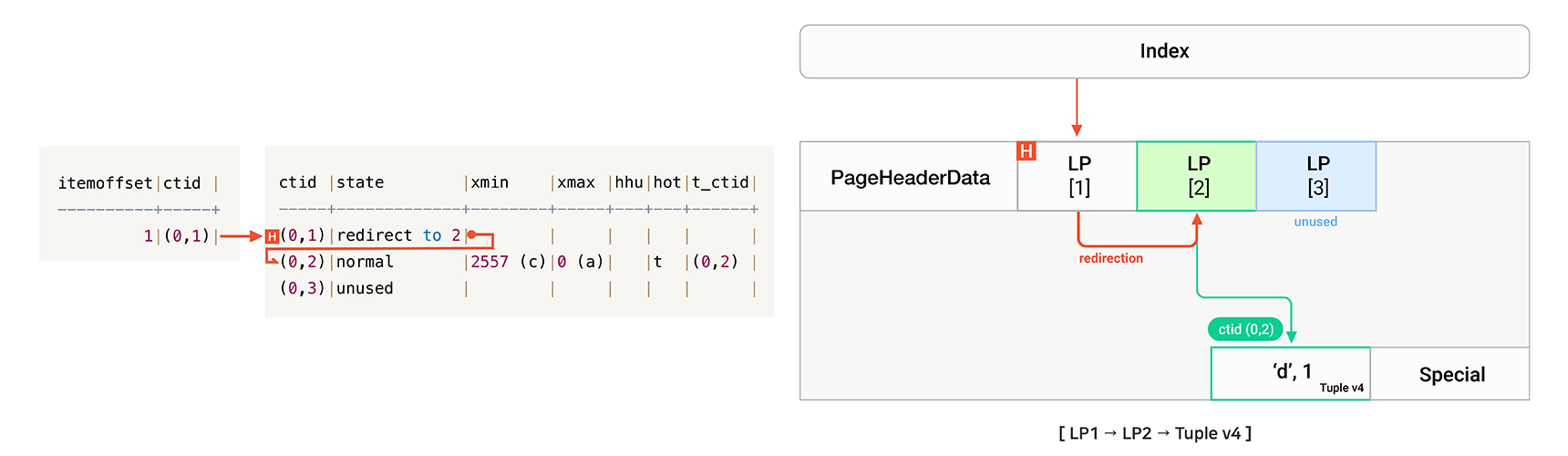
사용자가 테이블 t2에 대해 Vacuum을 수행하면 Dead Tuple을 제거하고 관련된 LP도 정리합니다. 또한 Head에서 LP2로 Redirection을 설정하고, LP2의 Offset은 위치 변화된 Tuple v4를 가리키도록 수정합니다. 이 모든 과정은 Case 1-6과 동일합니다.
2-7. Update 수행
update t2 set c1='e';
이후 다시 HOT Update가 수행되면, 새로운 버전 Tuple v5를 추가 생성합니다. 해당 페이지에 재사용 가능한 LP가 있다면 재사용하며, 그렇지 않다면 LP도 추가 생성해야 합니다. 위 그림에서는 LP3를 재사용하여 Tuple v5를 가리키는 데 사용하였다는 것을 알 수 있습니다. 이 모든 과정은 Case 1-7과 동일합니다.
Case 3. 인덱스에 포함된 컬럼에 Update 수행
마지막으로, Case 3에서는 Case 2와 달리 인덱스에 포함된 컬럼을 Update 하는 경우에 대해 알아볼 것입니다.
Case 2를 제외한, 인덱스를 갖는 테이블에 대한 Update는 해당 테이블에 생성된 모든 인덱스의 Update를 트리거합니다. 이는 새로 생성된 버전의 Tuple을 참조하기 위한 인덱스 엔트리를 추가해야 하기 때문입니다.
해당 Case는 HOT Update의 제약조건에 위배되므로 일반적인 Update 방식으로 동작할 것입니다. Case 1,2와 달리 일반적인 Update로 동작했을 때의 동작과정 및 HOT Update와의 차이점을 눈여겨보기 바랍니다.
3-1. 테이블 & 인덱스 생성
create table t3 (c1 char(2000),c2 integer) with (fillfactor=60);
create index t3_idx on t3(c1);3-2. Insert 수행
insert into t3 values('a',1);
새로운 Tuple을 Insert 하면 테이블 페이지의 빈 공간에 Tuple을 생성하며 인덱스 페이지에도 해당 Tuple에 대한 키값을 추가합니다.
3-3. Update 수행
update t3 set c1='b';
update t3 set c1='c';
3-1에서 Insert 한 Tuple에 Update를 수행하면, Tuple v1의 새로운 버전인 Tuple v2, Tuple v3를 생성합니다. 그리고 인덱스에 포함된 컬럼에 대한 Update가 발생했으므로, 인덱스 페이지에는 추가로 생성된 Tuple을 가리키기 위한 인덱스 엔트리가 추가됩니다.
위의 결과에서 보듯, 일반적인 Update로 수행되는 경우 hhu 및 hot값이 설정되지 않고 HOT Chain이 발생하지 않음을 확인할 수 있습니다.
📢 t_ctid는 해당 Tuple에 대하여 다음에 수행된 Update로 생성된 버전의 Tuple을 가리키는 간접 주소(포인터)로 사용하는 값입니다. HOT Update 시에는 HOT Chain을 구성하는 중요한 값이지만, 위와 같이 일반적인 Update의 경우에는 각기 서로 다른 인덱스 엔트리를 통해 접근하기 때문에, 단순히 최신 버전여부를 확인하는 데 사용됩니다.
3-4. Select 수행 ( * Single-page Vacuuming 트리거)
select * from t3;
c1 |c2|
----+--+
c | 1|
t3 테이블 조회를 위해 페이지에 Access 했을 때, 설정한 Fillfactor 값을 초과한 상태이므로 Single-page Vacuuming을 트리거합니다. Dead Tuple인 Tuple v1와 Tuple v2를 제거하고 해당 Tuple이 가리키던 LP1과 LP2는 dead 상태로 변경됩니다.
이때 Single-page Vacuuming의 경우 그 동작 대상이 테이블 페이지만으로 국한되기 때문에, 인덱스가 현재 참조 중인 LP1과 LP2는 바로 제거되지 않으며 인덱스에 대한 Update도 일어나지 않습니다.
📢 Dead Tuple을 제거하면서 해당 Tuple을 가리키고 있던 LP를 정리할 때, 해당 LP를 참조하고 있는 인덱스가 없다면 unused 상태로 표시하여 즉시 재사용 가능하게 합니다. 하지만, 해당 LP를 참조하고 있는 인덱스가 있다면 바로 해제할 수 없으므로 dead 상태로 표시하며 dead 상태의 LP는 재사용이 불가합니다. (이후 Vacuum 수행 등으로 인덱스에 대한 참조가 정리되면 unused 상태로 변경되어 재사용됩니다.)
3-5. Update 수행
update t3 set c1='d';
같은 Tuple에 대해 Update를 다시 수행하면, 새로운 버전인 Tuple v4를 생성하고, 인덱스 페이지에는 이에 대응하는 인덱스 엔트리가 추가됩니다. 인덱스 페이지 내 엔트리는 테이블 페이지의 Tuple을 식별할 수 있는 정보(ctid)를 가지고 있는데, INDEX_PAGE (’T3_IDX’, 1) 결과에서 보듯, Tuple이 추가 생성될 때마다 인덱스 페이지에 ctid정보가 추가됩니다. 인덱스 스캔이 발생 시, ctid를 확인하여 연결된 테이블 페이지의 LP 상태가 dead라면 해당 버전의 Tuple이 더 이상 존재하지 않음을 알고 다음으로 넘어갑니다.
Update가 반복적으로 수행되면 Dead Tuple은 증가합니다. 이러한 Dead Tuple은 Single-page Vacuuming을 통해 제거될 수 있지만, 사용했던 LP들(LP1, LP2)의 경우 dead 상태로 표시되므로 재사용되지 못하고 계속 남아있습니다.
3-6. 테이블 전체에 대한 VACUUM 수행
vacuum t3;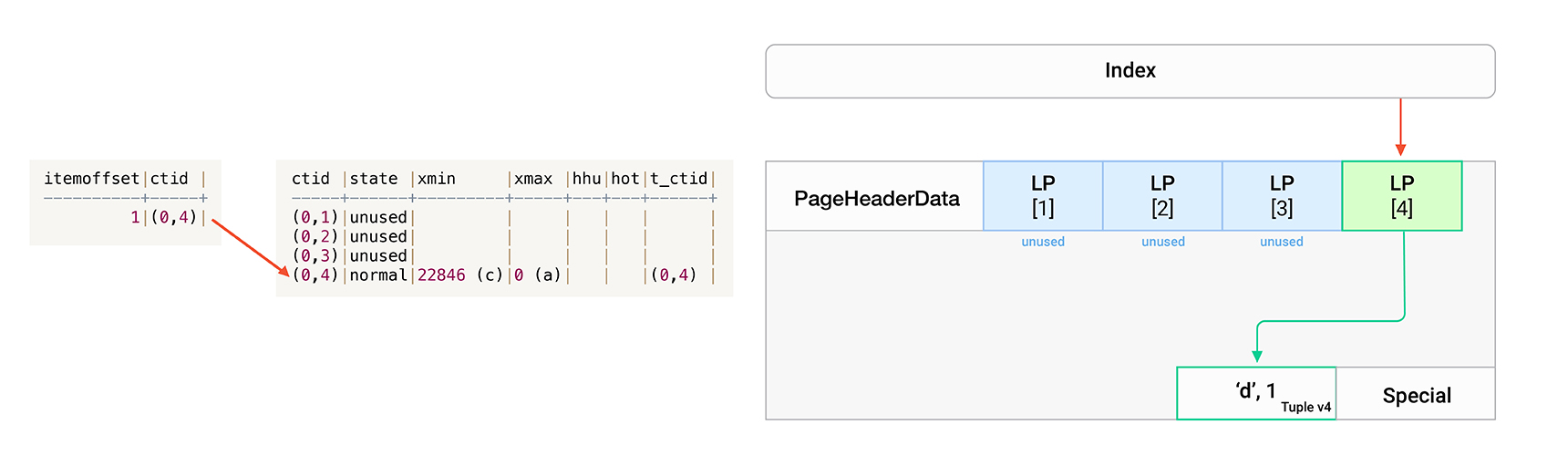
테이블 전체에 대한 Vacuum수행 시 Single-page Vacuuming작업과 마찬가지로 Dead Tuple을 제거하고 이를 가리키던 LP와의 연결을 해제합니다.
단, Single-page Vacuuming과 달리 Vacuum작업은 인덱스에 대한 정리작업도 수반되므로, Dead Tuple 및 Dead상태의 LP를 가리키던 인덱스 엔트리들까지 모두 정리됩니다. 이처럼 인덱스에 의한 참조되지 않는 LP들은 더 이상 dead상태가 아니며, 재사용 가능한 상태(unused)로 변경된다는 차이점이 존재합니다.
📢 Update Type과 Vacuum Type
Case 1, Case 2같이 HOT Update로 생성된 Tuple들은 페이지 외부에서 직접 참조되지 않으므로, Single-page Vacuuming 수행만으로도 Dead Tuple과 LP를 정리하여 페이지를 재사용 가능한 상태로 구성할 수 있습니다. 이는 Vacuum 및 Single-page Vacuuming이 동일한 역할을 수행하였음을 의미합니다.
하지만 Case 3과 같이 일반적인 Update의 경우, 인덱스 페이지에서 참조하는 LP에 대한 정리는 오로지 Vacuum을 통해서만 가능합니다.
즉, 온전한 테이블 페이지의 재구성을 위해서는, HOT Update 페이지의 경우 Single-page Vacuuming작업만으로도 충분하지만, 일반 Update가 발생한 페이지라면 dead 상태의 LP를 unused로 변경하기 위한 추가적인 Vacuum 작업이 필요합니다.
3-7. Update 수행
update t3 set c1='e';
이후 같은 Tuple에 대하여 또다시 Update를 수행하면, 새로운 버전의 Tuple v5를 생성합니다. 이때 LP는 재사용 가능한 LP1, LP2 그리고 LP3가 있으므로 추가 생성하지 않고 LP1를 먼저 재사용합니다. Tuple v5를 가리키는 LP1(0,1)에 대한 정보는 인덱스 페이지에 추가된 것을 확인할 수 있습니다.


기획 및 글 | 플랫폼기술연구팀
'엑셈 경쟁력 > DB 인사이드' 카테고리의 다른 글
| DB 인사이드 | PostgreSQL Replication - 구성 (0) | 2023.05.25 |
|---|---|
| DB 인사이드 | PostgreSQL Replication - 종류 (1) | 2023.04.27 |
| DB 인사이드 | PostgreSQL HOT - 1. Page와 관리 (1) | 2023.02.22 |
| DB 인사이드 | PostgreSQL Vacuum - Monitoring : XMIN’s Horizon (2) | 2023.01.19 |
| DB 인사이드 | PostgreSQL Setup - Migration & Upgrade 성능 및 주의사항 (0) | 2022.11.23 |




댓글