
Part. 1에서는 KNIME에 대해 간략하게 설명해 드렸어요!
이번 시간에는 데이터 분석의 첫 단계인 데이터 전처리에 대해 말씀드릴게요.
Q1. 데이터도 알겠고, 처리도 알겠는데, 전처리는 뭔가요?
A1.
전처리라는 용어는 말 그대로 ‘전’ + ‘처리’, 작업을 하기 전 원재료를 가공하는 것을 말해요. 영어로는 ‘preprocessing’ 이라고 하죠! 예를 들면, 데이터의 형태를 통일시켜야 할 때가 있어요!

왼쪽 생년월일을 보면 여러 형식으로 저장되어 있어요! 모든 방식이 날짜를 뜻하지만, 숫자의 길이도 다르고 숫자 사이를 구분하는 문자(‘-‘ 나 ‘/’)도 다르죠? 보기에도 힘들고, 컴퓨터조차 날짜로 인식하지 못해요. 예시처럼 왼쪽 생년월일과 같은 데이터를 오른쪽 생년월일과 같은 데이터로 만들어주는 작업이 바로 전처리예요! 데이터 전처리 중에 극히 일부분이니 이 부분 참고해주세요.
Q2. 저 정도면 엑셀로 하면 되는 거 아닌가요?! 굳이 KNIME을 사용해야 할 필요가 있을까요?!
A2.
맞아요! 위의 예시처럼 간단한 전처리라면 엑셀이 편하고 빠를 거예요! 하지만 위의 예시와 같은 데이터가 수백, 수천만 개가 있다면? 우리는 속성도 다양하고, 개수도 많은 데이터를 만나게 돼요. 그런 경우에는 KNIME으로 데이터 전처리를 빠르고 효율적으로 할 수 있어요.
그리고 우리의 궁극적인 목적은 데이터 전처리가 아닌 데이터 분석이기에 전처리부터 분석까지 한 번에 할 수 있는 KNIME을 이용한다면 훨씬 편리하겠죠?
Q3. 전처리의 종류는 어떤 것들이 있나요?
A3.
데이터 전처리의 종류에는 여러 가지가 있지만, 대표적인 것들을 나열해보면 데이터 유형 변환, 중복 제거, 결측치 처리, 이상치 처리, 스케일링이 있어요. 앞에서부터 차례대로 설명할게요.
1) 데이터 유형 변환 : 앞에서 든 간단한 예시처럼 같은 속성(생년월일) 내에서 형식이 다를 때 동일하게 변경하는 것을 말해요. 엑셀에서 서식을 통일하는 것과 비슷해요! 예를 들어, 아래 '주문일시'처럼 형식이 다른 두 데이터가 있다고 할게요.

왼쪽 테이블은 주문일시가 날짜이고, 오른쪽 테이블은 주문일시가 날짜와 시간이죠? 두 데이터를 합쳐서 분석하려면 데이터의 형식이 같아지도록 만들어줄 필요가 있어요. '주문일시'의 자료형이 문자열이라고 할 때, 형식을 맞추는 작업은 아래와 같이 할 수 있어요.

KNIME의 'String to Date/Time' 기능을 이용해 자료형을 날짜로, 형식을 'yyyy-mm-dd'로 바꿨어요.

2) 중복 제거 : 중복 데이터를 제거한다는 것은 너무 중요해요. 중복된 데이터로 인해 분석 결과가 한쪽으로 치우칠 수 있어요. 예를 들어볼게요! 아래의 표를 보면 피그렛(여/11세/6월 15일)이 두 회원번호를 가지고 있어요. 한 사람이 두 번 가입해서 생긴 중복이라 가정할게요.
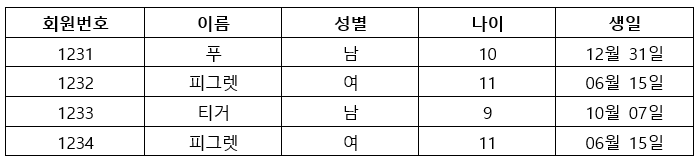
회원의 성별, 연령대를 분석하려면 이런 경우를 제거해줄 필요가 있어요. 이 작업은 KNIME으로 손쉽게 가능해요.

KNIME의 'Duplicate Row Filter'를 이용하면 어떤 속성(들)을 기준으로 중복을 판단할 건지 지정해서, 간단하게 필터링할 수 있답니다.

데이터가 많을 땐 모든 행을 눈으로 낱낱이 확인할 수 없기에, 중복은 사전에 처리해주세요. 동시에 데이터를 제거하는 것은 신중하게 결정해야 해요.
3) 결측치 처리 : 결측치란, 값이 존재하지 않는 데이터를 말해요. 데이터 수집 과정의 기술적인 이유나 잘못된 데이터 전처리, 또 값을 비워둘 수밖에 없었던 데이터의 특성 등 다양한 원인으로 결측치가 생길 수 있어요. 아래 예시는 좀 극단적으로 결측이 있는 가상의 데이터예요. 예시를 토대로 결측치를 처리하는 방법을 알아볼게요.

우선, 가장 먼저 값이 하나도 없는 행을 봐주세요. 바로 위 ‘날짜’가 10월 29일이고, 아래가 10월 30일이므로 이 행(Row)은 단순 제거할게요. 다음으로 ‘강수’가 비어 있는 곳을 봐주세요. 모두 ‘강수 확률’이 0인 경우예요. 그렇다면 이 결측은 ‘X’로 채워줄게요. 마지막으로 ‘기온’이 비어 있는 곳을 봐주세요! 기온은 보통 연속적이므로 직전 기록과 직후 기록의 평균으로 채우면 어떨까요?

KNIME의 'Missing Value'를 통해 한 번에 다양한 결측치를 처리할 수 있어요.
보기도 좋고 편리하죠!

딥러닝, 머신러닝 같은 데이터 모델링을 위해선 결측을 반드시 처리해주어야 해요. 동시에 존재하지 않는 값을 만들어내는 건 데이터를 왜곡할 수 있기 때문에 아주 아주 신중하게 해야 해요!
4) 이상치 처리: 이상치란 다른 값들에 비해 아주 작거나 큰 값을 말해요. 다시 말하면 기존 값의 분포에서 벗어난 값을 말하죠! 이상치가 있는 데이터를 그대로 사용해서 데이터 분석 모델링을 하면, 컴퓨터에게 혼란을 줄 수 있어요. 그래서 데이터 분석을 하기 전 이상치에 특별한 처리를 하곤 해요. 예를 들어 아래와 같은 데이터가 있다고 가정할게요.
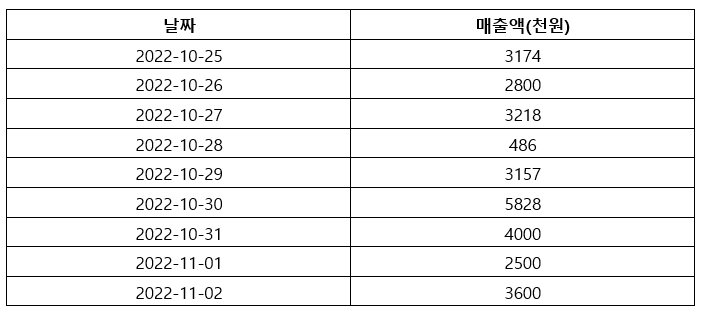
위 데이터의 차트를 그려보면 아래와 같아요.

파란색 동그라미는 아까 봤던 매출표의 486(천원)과 5828(천원)을 의미하죠. 두 그래프의 1,000 이하의 값과 6,000에 가까운 값이 보이나요? 그래프로 보니 다른 값들의 분포에서 많이 벗어나는 게 보이죠? 이렇게 이상치를 판별하고, 제거하는 작업을 KNIME으로 할 수 있어요.

사분위수(IQR)을 이용하여 이상치를 판정하고 제외해주었어요. 이상치는 단순 제거할 수도 있지만 다른 값으로 대체하여 사용하기도 한답니다.

5) 스케일링: 여러 데이터를 가지고 분석할 때, 데이터 범위가 제각기 다르면 안돼요. 데이터의 범위나 분포를 적합하게 변형할 필요가 있죠. 예를 들어, 가로 길이와 세로 길이의 데이터가 있을 때, 가로 길이는 'cm' 단위이고, 세로 길이는 'm' 단위라면 통일해줘야 해요.
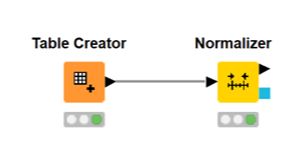
KNIME의 'Normalizer'는 다양한 스케일링 방식(Min-max Normalization, Z-score Normalization, Normalization by decimal scailing)을 지원한답니다.
Q4. 위에서 설명하는 것을 보면 한 데이터셋에 대한 전처리 같은데, 데이터셋이 여러 개일 때는 어떻게 하나요?
A4.
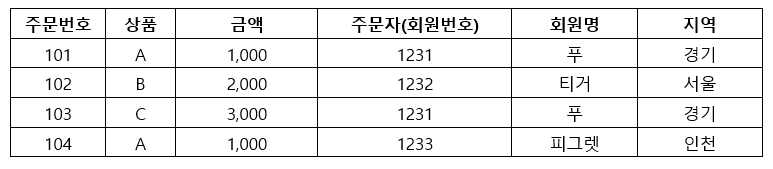
맞아요! 보통 데이터베이스에서 JOIN과 같은 기능으로 여러 개의 데이터 셋을 병합하여 다루는 작업을 많이 하죠. 이 또한 하나의 전처리라고 할 수 있어요. 아래의 예시로 확인해볼까요!? 아래와 같이 주문내역, 회원 리스트의 두 데이터가 있다고 할게요.

왼쪽 주문내역의 '주문자' 속성이 오른쪽 회원 리스트의 '회원번호'와 같다고 할 때, 주문내역에 회원 정보를 합쳐볼게요.
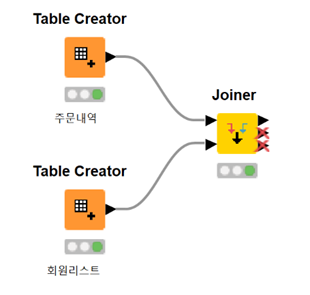
KNIME의 Joiner를 이용하면 여러 데이터를 하나의 데이터로 합칠 수 있어요.
여기까지 KNIME으로 데이터 전처리를 하는 방법을 간략하게 알아봤어요.
다음 편에는 데이터 시각화에 대한 콘텐츠로 찾아올게요. 궁금하거나 자세하게 알고 싶은 내용은 OWLEYE(링크)를 통해 문의하시면 더욱 자세히 말씀드릴게요.

글 | 빅데이터 분석팀 김지호, 신혜지
'엑셈 경쟁력 > Knock, Knock! KNIME' 카테고리의 다른 글
| KNIME | KNIME을 활용한 텍스트 분석 (0) | 2023.06.29 |
|---|---|
| KNIME | KNIME을 활용한 이미지 분석 (0) | 2023.04.27 |
| KNIME | 잘 안 보이니까 시각화 해주세요! (0) | 2023.02.22 |
| KNIME | KNIME이라고 들어봤어요? (0) | 2022.09.27 |




댓글