

PostgreSQL SQL 처리과정
본 문서에서는 PostgreSQL의 SQL처리과정에 대해 알아보도록 하겠습니다.
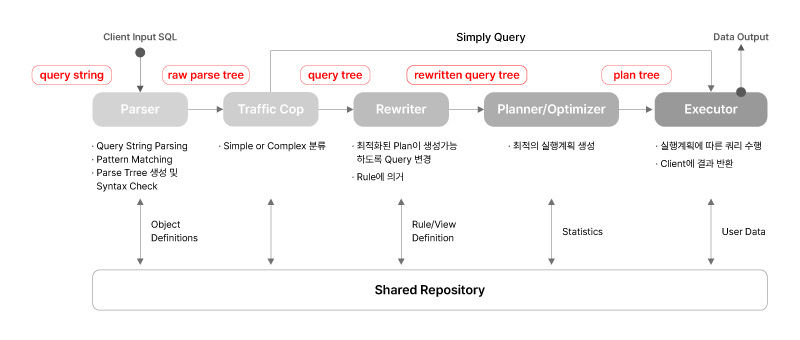
postgres 프로세스는 Client로부터 SQL(Query string)을 전달받으면 아래와 같은 5개의 과정을 거쳐 SQL을 처리하며 그 결과를 Client로 반환합니다. 각 과정에서는 문법체크 및 의미분석, 최적화 작업 등을 수행하며, 세부적인 내용을 각각 확인해 보도록 하겠습니다.
Parser
Parsing 단계는 SQL 처리과정의 첫번째 단계로 Query 구문을 분석하여 Syntax Error를 체크하고 Parse Tree를 생성합니다. 해당 단계에서는 System Catalog를 참조하지 않기 때문에 개별 요소들에 대한 의미분석(Semantic)이 불가하며 단순한 문법체크(Syntax)만을 수행합니다.
📌 시스템 카탈로그(System Catalog)는 테이블, Row, Schema 등의 메타데이터 정보를 저장하는 장소로 다른 RDBMS에서는 Data Dictionary로 표기하기도 합니다.

Traffic Cop (Analyzer)
Parser 단계에서 생성된 Parse tree의 의미를 분석하여 Query Tree를 생성합니다. SQL이 참조하는 테이블, 함수 및 연산자를 이해하기 위한 의미분석(Semantic)과정을 수행합니다. Query Rewrite나 최적화가 필요하지 않은 Simple Query의 경우 바로 Executor 단계로 넘어갑니다.
- Simple Query : create, drop, alter, vacuum 등의 제어문
- Complex Query : select, join 과 같은 그 외의 Query

Rewriter
Traffic Cop단계에서 생성된 Query Tree에 사전 정의된 Rule을 적용하여 Query를 단순화합니다. 입력, 출력 모두 Query Tree입니다.
Query Rewrite 기법
- Subquery Collapse
- Subquery를 Main Query에 병합합니다. (Subquery Unnest)
- View Merging
- View 또는 Inline View를 풀어서 테이블 간 조인으로 변경합니다.
- View Merging이 가능한 경우 테이블 간 다양한 조인 방법 및 순서를 선택할 수 있습니다.
- Simple View는 항상 View Merging에 성공하지만 Complex View는 항상 실패합니다.
- View 또는 Inline View를 풀어서 테이블 간 조인으로 변경합니다.
- JPPD (Join Predicate Push-Down)
- View Merging이 실패한 경우 Join Predicate를 View 내부로 Push Down 하는 방법입니다.
- Join Predicate는 상수 조건이어야 Push Down이 가능 합니다.
- Lateral View를 사용해야 합니다.
- View Merging이 실패한 경우 Join Predicate를 View 내부로 Push Down 하는 방법입니다.
📌 Simple View와 Complex View
View 내부에 GROUP BY, DISTINCT와 같은 Aggregation을 사용하지 않은 경우를 Simple View라고 하며 반대의 경우를 Complex View라고 합니다.
Planner (Optimizer)
최적의 실행계획을 생성하는 단계입니다. 선택 가능한 모든 Plan Path를 만들어 각 Path의 Cost를 계산하며 그 중 가장 적은 Cost를 갖는 Plan을 선택합니다. 이때 주요 결정사항(Key Decisions)으로는 Scan 및 Join Method가 있습니다.
- Path 단위 기준은 SCAN, JOIN, GROUP BY, SORTING, AGGREGATION 등이 있습니다.
- Cost는 System Catalog에 저장된 통계정보를 기반으로 합니다. (pg_class, pg_statistics)
key Decisions
Scan Method
- Sequential Scan
- 테이블을 Full Scan하면서 레코드를 읽습니다.
- 인덱스가 존재하지 않거나 선택할 수 없을 때 Sequential Scan을 선택합니다.
- Bitmap Index Scan
- 테이블 랜덤 액세스 횟수를 줄이기 위해서 고안된 방식입니다.
- 인덱스 컬럼에 대한 테이블 레코드의 정렬 상태를 Correlation이라고 하며, Correlation이 좋으면 Index Scan을, 나쁘면 Bitmap Index Scan 방식을 선택합니다.
- Bitmap Index Scan 방식은 Block 번호 순으로 Block을 정렬한 후 Access 합니다. 때문에 Index Key 순으로 출력되지 않습니다. (정렬이 보장되지 않습니다)
- Index Scan
- Index Leaf Block에 저장된 Key를 이용하여 레코드를 읽습니다.
- 레코드의 정렬 상태에 따라 Block Access 횟수가 크게 차이 납니다.
- Index Key 순으로 출력됩니다. (정렬이 보장됩니다)
Join Method
- Nested Loop Join
- Outer(Driving) 테이블을 Access한 후에 Inner(Driven) 테이블을 반복적으로 Access 하며 조인을 수행합니다.
- Hash Join
- Inner 테이블의 조인키를 이용하여 Hash Table을 생성하고, Outer 테이블을 Access하면서 Hash Table 결과와 조인을 수행합니다.
- Sort Merge Join
- Outer 테이블과 Inner 테이블에서 각각 조건에 만족하는 레코드를 추출한 후, 조인 키를 기준으로 정렬작업을 수행합니다.
- 정렬된 결과를 이용하여 조인을 수행하며 조인에 성공하면 추출 버퍼에 넣은 뒤 출력합니다.
📌 Correlation은 Oracle의 Clustering Factor와 동일한 개념으로 인덱스와 테이블의 유사도를 의미합니다.
Executor
실행계획에 따라 Query를 수행하고 그 결과를 Client에 전달합니다. 쿼리를 처리할 때 미리 할당된 temp_buffers 및 work_mem과 같은 일부 메모리 영역을 사용하며 필요에 따라 임시 파일(Temp)을 생성할 수 있습니다.


기획 및 글 | 플랫폼기술연구팀
'엑셈 경쟁력 > DB 인사이드' 카테고리의 다른 글
| DB 인사이드 | PostgreSQL Architecture - 4. 동작 원리 (0) | 2022.04.27 |
|---|---|
| DB 인사이드 | PostgreSQL Architecture - 2. Physical Structure (0) | 2022.04.27 |
| DB 인사이드 | PostgreSQL Architecture - 3. Logical Structure (2) | 2022.04.27 |
| DB 인사이드 | PostgreSQL 참고자료 - Configuration File : pg_hba.conf (0) | 2022.03.30 |
| DB 인사이드 | PostgreSQL 참고자료 - Configuration File : postgresql.conf (0) | 2022.03.30 |




댓글